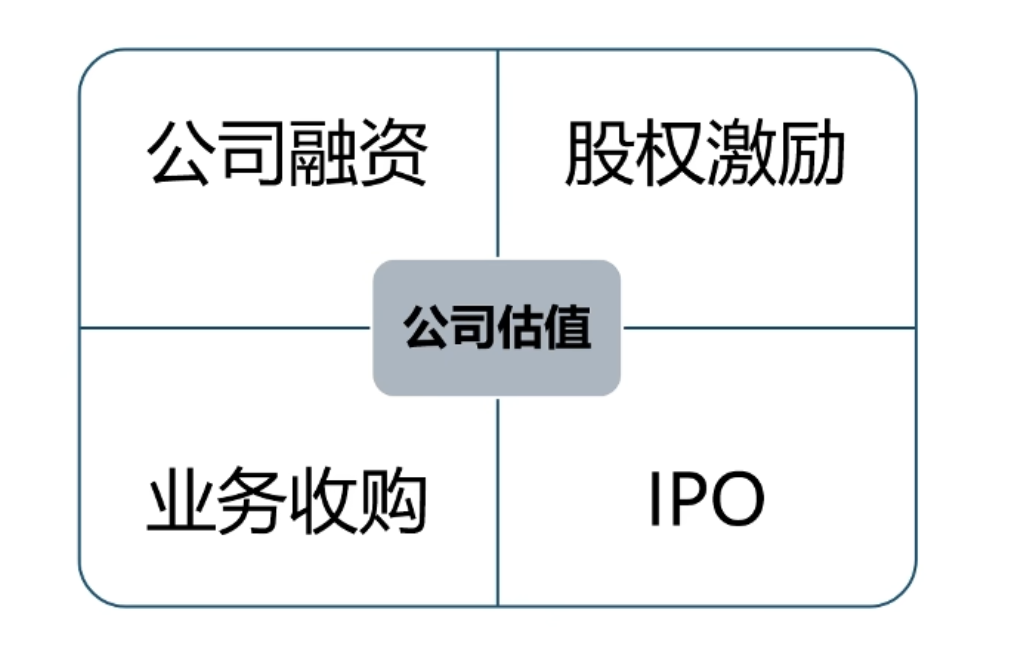
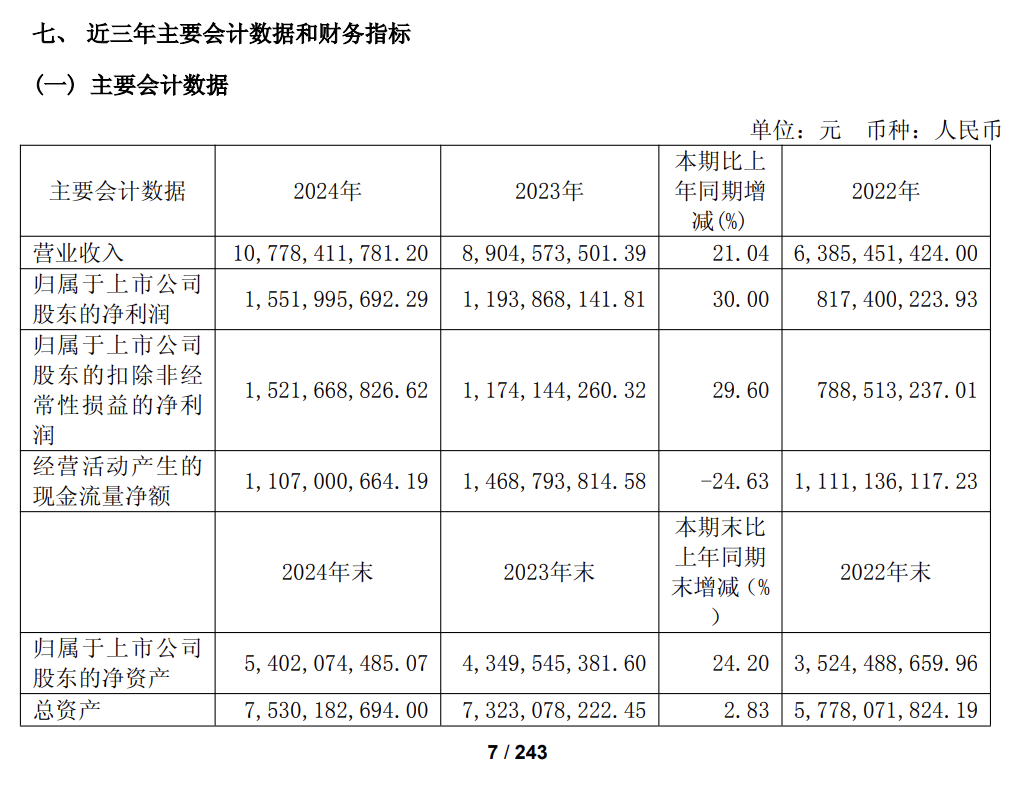
如何给公司估值
· 18 min read
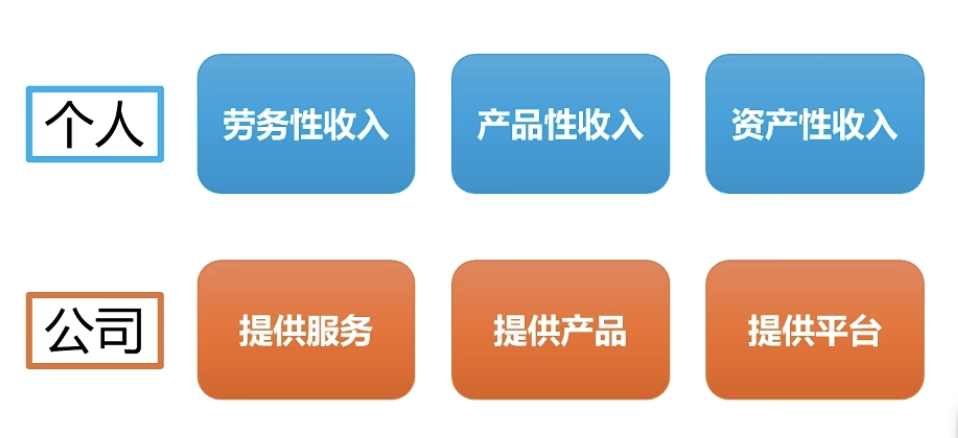
如果你输入的都是垃圾,输出的也是垃圾。垃圾信息本身也没办法作为思考的原料。
一个残酷的现实是,现在百分之 99.99 的信息都是垃圾,并不是说现实中真的有百分之 99.99,而是我们因为被动的信息获取位置和获取习惯,习惯性的从别人那里接受信息,或者是网上的自媒体,机器的算法想让我们知道的信息,而这些信息并不是我们想要的,所以对我们来说是垃圾信息。
最近刚回国,辛辛苦苦应聘终于入职了新公司,中间有段跌宕起伏的过程,着实辛苦了点。
这几个月,应该是我最"佛系"的几个月份。很多东西还是处在混乱状态,很多资料的转移,很多行政工作需要处理,要不要租房,要不要更换个新手机,要不要买些工作用的衣服,朋友们开启一轮火热的约饭局等等。世界总是在我不忙的时候什么对我置之不理,在我忙起来的时候,却不看看我有多少的处理能力,实在不太"地道"。
总结下几个事情,也是我在浑浑噩噩中关注到的几个点:
要说在工作的内容是否有变化,我的感觉是其实没有很大的变化,我在国外是来解决问题的人,我在国内也是来解决问题的人,我其实需要做的事情是一样的,动用的能力大差不差的,只是行业有别。
这个过程中我发现,要想把事情做的更大更好,只在自己的摊子里面去做并不一定是好的选择。这个尤其是我在加入这个新团队,并且与多位 managers 交流沟通被给予的诸多"相同"的建议里面被反复强调的。