Kubernetes 理论与实践-6-状态持久化-State
前文回顾
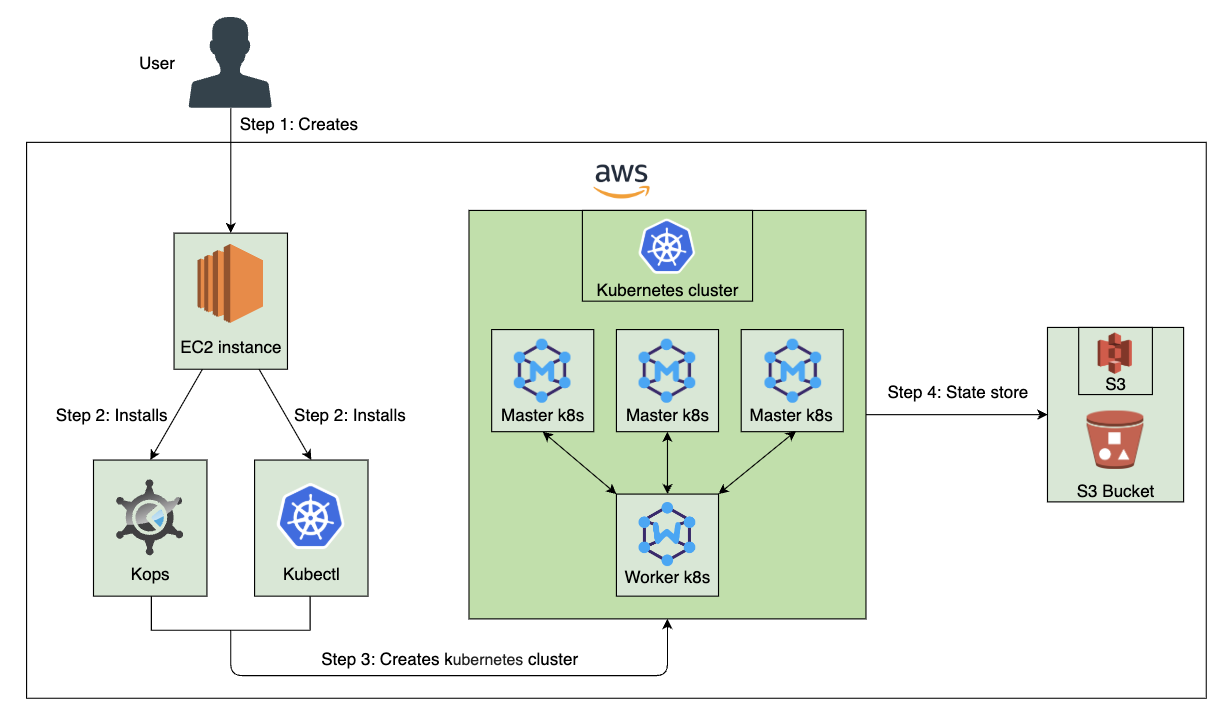
Kubernetes 理论与实践-5-搭建生产环境集群-kOps, AWS
我们要构建容错系统,需要确保系统的任何部分的故障都是可恢复的。另外由于速度至关重要,我们也不能靠人工抢修故障。
实践-初始化 Kubernetes 集群
通过 Auto Scaling Group,当节点故障后会重新创建失败节点,并且它们会安装 kOps 的启动进程,一切运行正常后,它们会加入集群。
这个系统不能够称之为高可用和容错性的,因为我们还无法解决故障期间保持状态的问题。我们应该如何保留我们的数据?
创建 Kubernetes 集群
找到之前保存的集群配置
cd cluster
cat kops
source kops # 将配置加载到环境变量中

创建 S3 存储桶
export BUCKET_NAME=devops23-$(date +%s)
aws s3api create-bucket \
--bucket $BUCKET_NAME \
--create-bucket-configuration \
LocationConstraint=$AWS_DEFAULT_REGION
export KOPS_STATE_STORE=s3://$BUCKET_NAME
创建集群
kops create cluster \
--name $NAME \
--master-count 3 \
--master-size t2.small \
--node-count 2 \
--node-size t2.medium \
--zones $ZONES \
--master-zones $ZONES \
--ssh-public-key devops23.pub \
--networking kubenet \
--yes
验证
kops validate cluster
# cluster devops23.k8s.local is ready
创建 Ingress 是和 ELB DNS
kubectl create \
-f https://raw.githubusercontent.com/kubernetes/kops/master/addons/ingress-nginx/v1.6.0.yaml
我们需要 ELB DNS 与 Ingress 配合工作。
CLUSTER_DNS=$(aws elb \
describe-load-balancers | jq -r \
".LoadBalancerDescriptions[] \
| select(.DNSName \
| contains (\"api-devops23\") \
| not).DNSName")
echo $CLUSTER_DNS
# ***.us-east-2.elb.amazonaws.com
实践-部署有状态应用(不持久化状态)
部署 jenkins
cat pv/jenkins-no-pv.yml
The Deployment injenkins-no-pv.yml:
其中,我们使用一个 volume 传递 secret。Jenkins 将其状态保存在 /var/jenkins_home 中,但是我们没有挂载该目录。
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkins
namespace: jenkins
spec:
selector:
matchLabels:
app: jenkins
strategy:
type: Recreate
template:
metadata:
labels:
app: jenkins
spec:
containers:
- name: jenkins
image: vfarcic/jenkins
env:
- name: JENKINS_OPTS
value: --prefix=/jenkins
- name: SECRETS_DIR
value: /etc/secrets
volumeMounts:
- name: jenkins-creds
mountPath: /etc/secrets
resources:
limits:
memory: 2Gi
cpu: 1
requests:
memory: 1Gi
cpu: 0.5
volumes:
- name: jenkins-creds
secret:
secretName: jenkins-creds
创建资源
kubectl create \
-f pv/jenkins-no-pv.yml \
--record --save-config

kubectl --namespace jenkins \
get events

因为没有找到 Secret, 所以创建失败。
创建 Secret
kubectl --namespace jenkins \
create secret \
generic jenkins-creds \
--from-literal=jenkins-user=jdoe \
--from-literal=jenkins-pass=incognito
verify
kubectl --namespace jenkins \
rollout status \
deployment jenkins
# The deployment "jenkins" is successfully rolled out
问题-有状态应用部署失败原因分析
打开网站 UI
open "http://$CLUSTER_DNS/jenkins"
创建任务
使用之前的 Secret 登陆,并创建一个作业:"my-job" 项目,选择 "pipeline" 类型,确定,保存。
模拟和分析故障
我们将终止 Pod 中运行的 Java 进程模拟失败,首先需要找到 Pod 名称:
kubectl --namespace jenkins \
get pods \
--selector=app=jenkins \
-o json
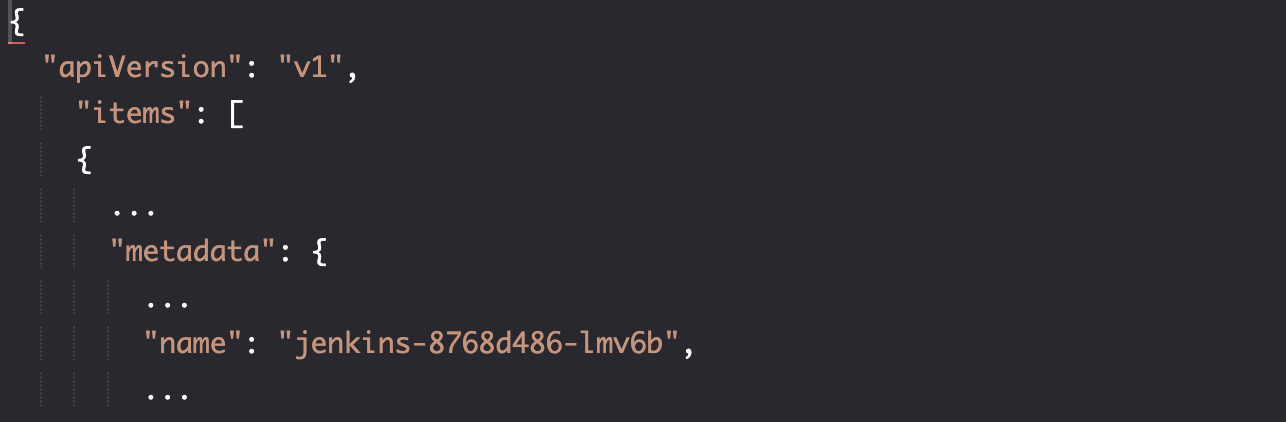
POD_NAME=$(kubectl \
--namespace jenkins \
get pods \
--selector=app=jenkins \
-o jsonpath="{.items[*].metadata.name}")
echo $POD_NAME # Output: jenkins-8768d486-lmv6b
一旦终止 java 后,Jenkins 进程会终止,容器会失败。Pod 中失败的容器将被重新创建。
kubectl --namespace jenkins \
exec -it $POD_NAME pkill java
一段时间,Jenkins 恢复后:
open "http://$CLUSTER_DNS/jenkins"
我们发现"my-job" 项目不见了。托管 /var/jenkins_home 目录的容器失败,并被替代,里面的 state 也被替代。
我们知道可以通过 volume 保存状态,但是之前用的是 emptyDir 挂载,这种卷同样会在失败后丢失现有 State。
定义-存储类型与选择
如果我们想持久保持状态,有两种选择:
- 本地存储 Local storage
- 外部存储 External storage
- 对象存储 S3 (x, 不适合用作本地磁盘)
- 弹性文件系统 EFS (Elastic File System)
- 弹性块存储 EBS (Elastic Block Store)
本地存储 Local storage
我们可以把本地存储数据复制到多个服务器上,使用本地存储即可保持住容器状态。
但是我们也会遇到如何保持个服务器上状态一致等问题,设置起来太复杂。
因此,更常用的方法是使用外部存储来保留状态。
外部存储 External storage
弹性文件系统 EFS
EFS 可用性高,它可以挂载到分布在多个可用区中的多个 EC2 实例。
但是 EFS 的性能有损失。它是一个网络文件系统,带有更高延迟。
弹性块存储 EBS
EBS 是我们在 AWS 中最快的存储。它的数据访问延迟非常低,性能的最佳选择。缺点是可用性,它不适用于多个可用区。
如果一个区域出现故障,则意味着停机,至少在区域恢复到其运行状态之前是这样。
这种情况,我们需要将 EBS 卷迁移到运行状况良好的区域。
选择
我们将选择 EBS 来满足我们的需要:
- Jenkins 严重依赖 IO,需要尽可能访问数据
- Kubernetes 支持 EBS 和 EFS (v1.17 版本开始支持)
- EBS 比 EFS 便宜
实践-创建 AWS EBS 卷
找到 worker 节点正在运行的区域
aws ec2 describe-instances
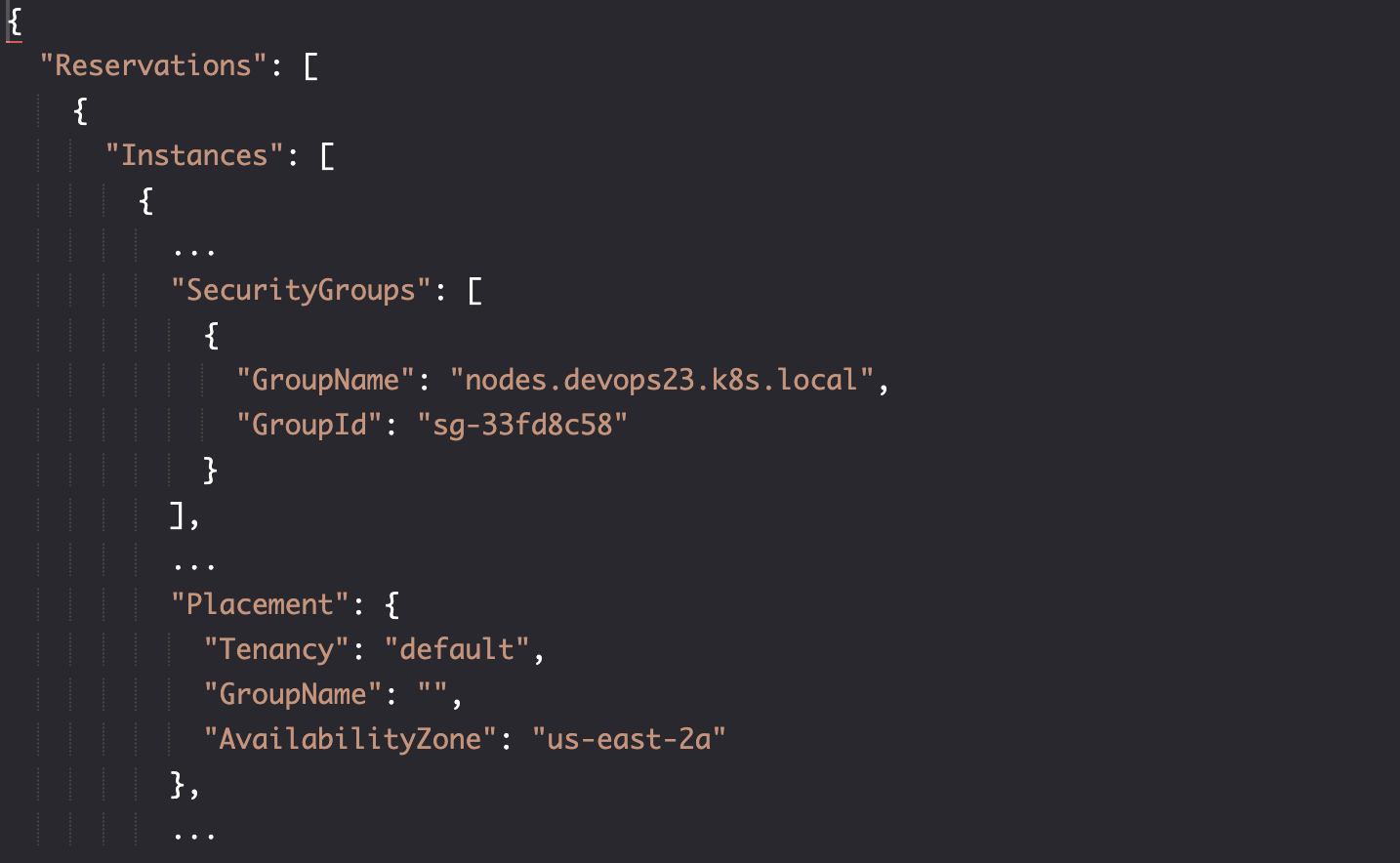
获取可用区
aws ec2 describe-instances \
| jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.Placement.AvailabilityZone"

设置环境变量
aws ec2 describe-instances \
| jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.Placement.AvailabilityZone" \
| tee zones
AZ_1=$(cat zones | head -n 1)
AZ_2=$(cat zones | tail -n 1)
创建卷
我们创建三个 EBS 卷,其中两个位于一个区域,而第三个位于另一个区域。它们都有 10GB 空间,gp2 类型 (其他类型要么更大,要么更昂贵)。
定义的标签将帮助我们区分此集群的卷和其他集群的卷。
VOLUME_ID_1=$(aws ec2 create-volume \
--availability-zone $AZ_1 \
--size 10 \
--volume-type gp2 \
--tag-specifications "ResourceType=volume,Tags=[{Key=KubernetesCluster,Value=$NAME}]" \
| jq -r '.VolumeId')
VOLUME_ID_2=$(aws ec2 create-volume \
--availability-zone $AZ_1 \
--size 10 \
--volume-type gp2 \
--tag-specifications "ResourceType=volume,Tags=[{Key=KubernetesCluster,Value=$NAME}]" \
| jq -r '.VolumeId')
VOLUME_ID_3=$(aws ec2 create-volume \
--availability-zone $AZ_2 \
--size 10 \
--volume-type gp2 \
--tag-specifications "ResourceType=volume,Tags=[{Key=KubernetesCluster,Value=$NAME}]" \
| jq -r '.VolumeId')
验证 verify
echo $VOLUME_ID_1 # vol-092b8980b1964574a
aws ec2 describe-volumes \
--volume-ids $VOLUME_ID_1
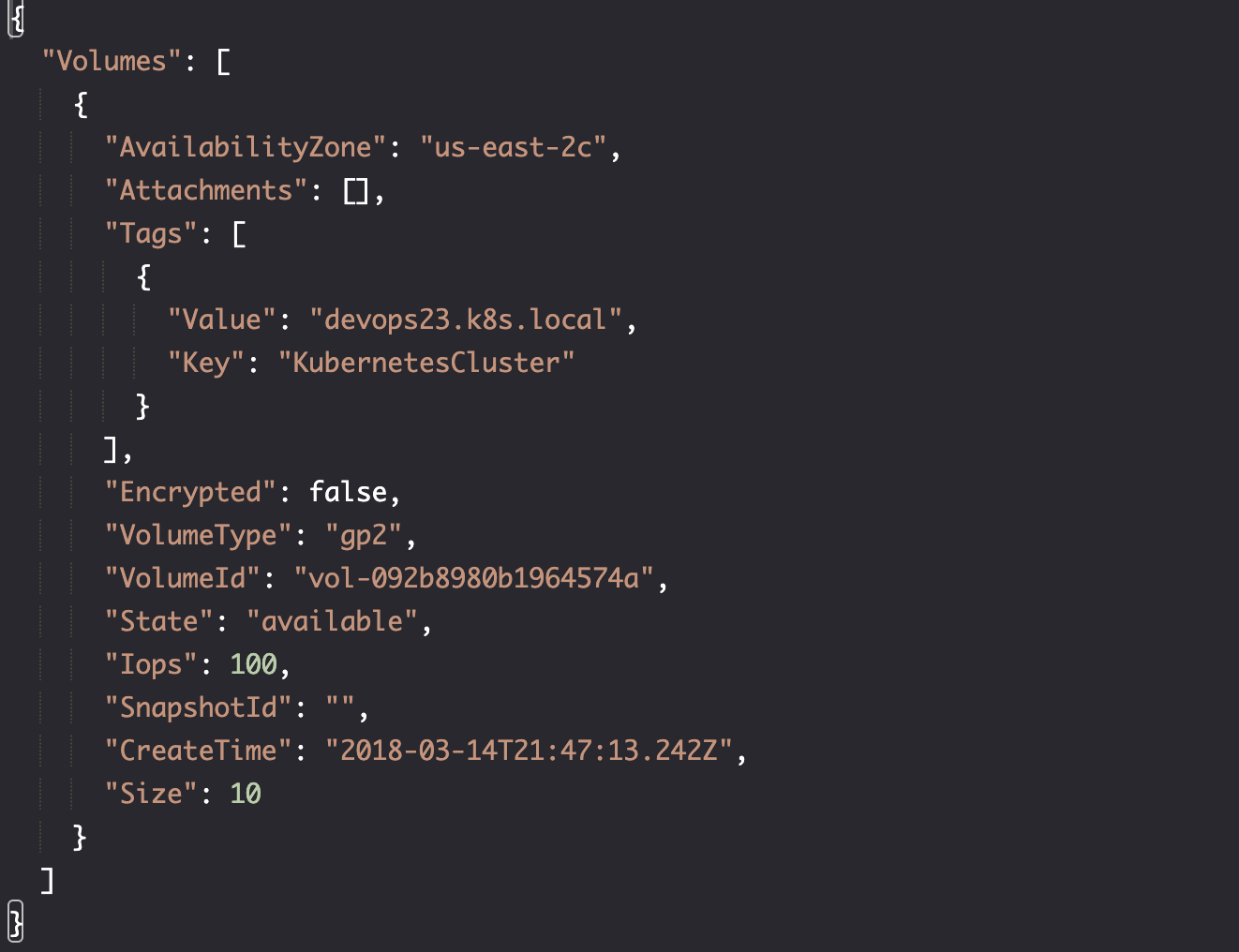
现在我们确定 EBS 已创建且可用,并且与 Worker 节点位于同一区域,我们可以创建 Kubernetes 持久性卷。
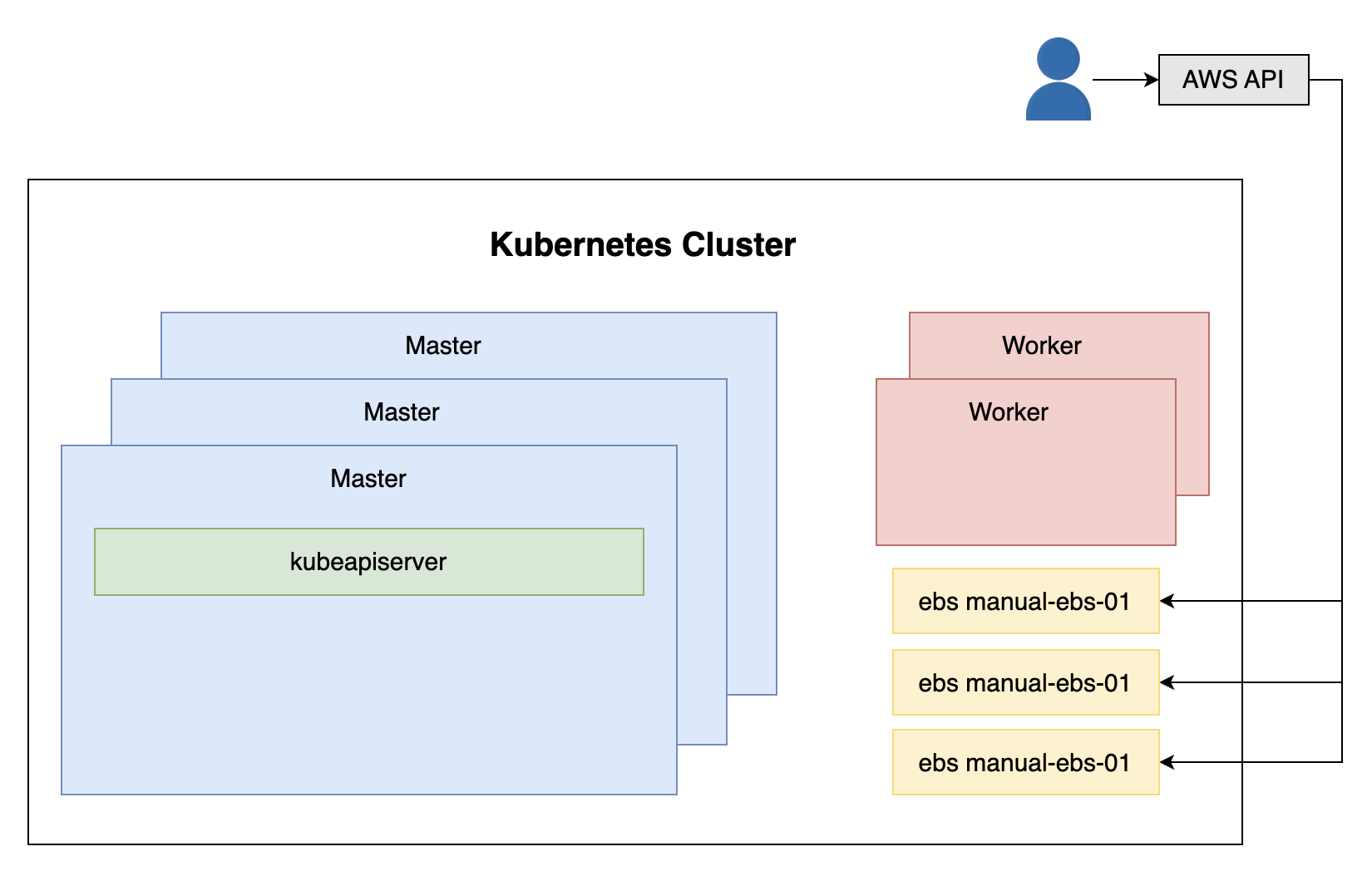
实践-创建 Kubernetes 持久卷
我们需要添加 PersistentVolumes 告诉 Kubernetes 我们在 AWS 上有 EBS 卷。
PersistentVolumes 允许我们将存储提供方式和使用方式的细节解耦抽象出来。与卷 Volumes 类似,PersistentVolumes 是 Kubernetes 集群中的资源。
主要的区别是它的生命周期独立于使用它的 Pods。
定义
# echo $VOLUME_ID_1 # vol-092b8980b1964574a
cat pv/pv.yml
kind: PersistentVolume
apiVersion: v1
metadata:
name: manual-ebs-01
labels:
type: ebs
spec:
storageClassName: manual-ebs
capacity:
storage: 5Gi
accessModes
- ReadWriteOnce
awsElasticBlockStore:
volumeID: REPLACE_ME_1 # 将被后面的指令替代
fsType: ext4
- 我们定义 PersistentVolume 大小为 5Gi, 我们知道 AWS 上卷的大小是 10Gi,PersistenVolume 大小定义可以是小于或等于 AWS 上卷的大小。
ReadWriteOnce: 在任何给定时刻,只有一个 Pod 能够使用它。我们还有ReadOnelyMany和ReadWriteMany的模式,要么是只读,要么读写,这两种模式适合 NFS。
其他存储平台
- AWS (当前)
awsElasticBlockStore
- Azure
azureDiskazureFile
- GCP-Google Compute Engine
GCEPersistentDisk
- Glusterfs: https://www.gluster.org/
- 如果此集群在本地数据中心运行,可以考虑使用
nfs
创建三个 PersistentVolumes:
cat pv/pv.yml \
| sed -e \
"s@REPLACE_ME_1@$VOLUME_ID_1@g" \
| sed -e \
"s@REPLACE_ME_2@$VOLUME_ID_2@g" \
| sed -e \
"s@REPLACE_ME_3@$VOLUME_ID_3@g" \
| kubectl create -f - \
--save-config --record
verify
kubectl get pv

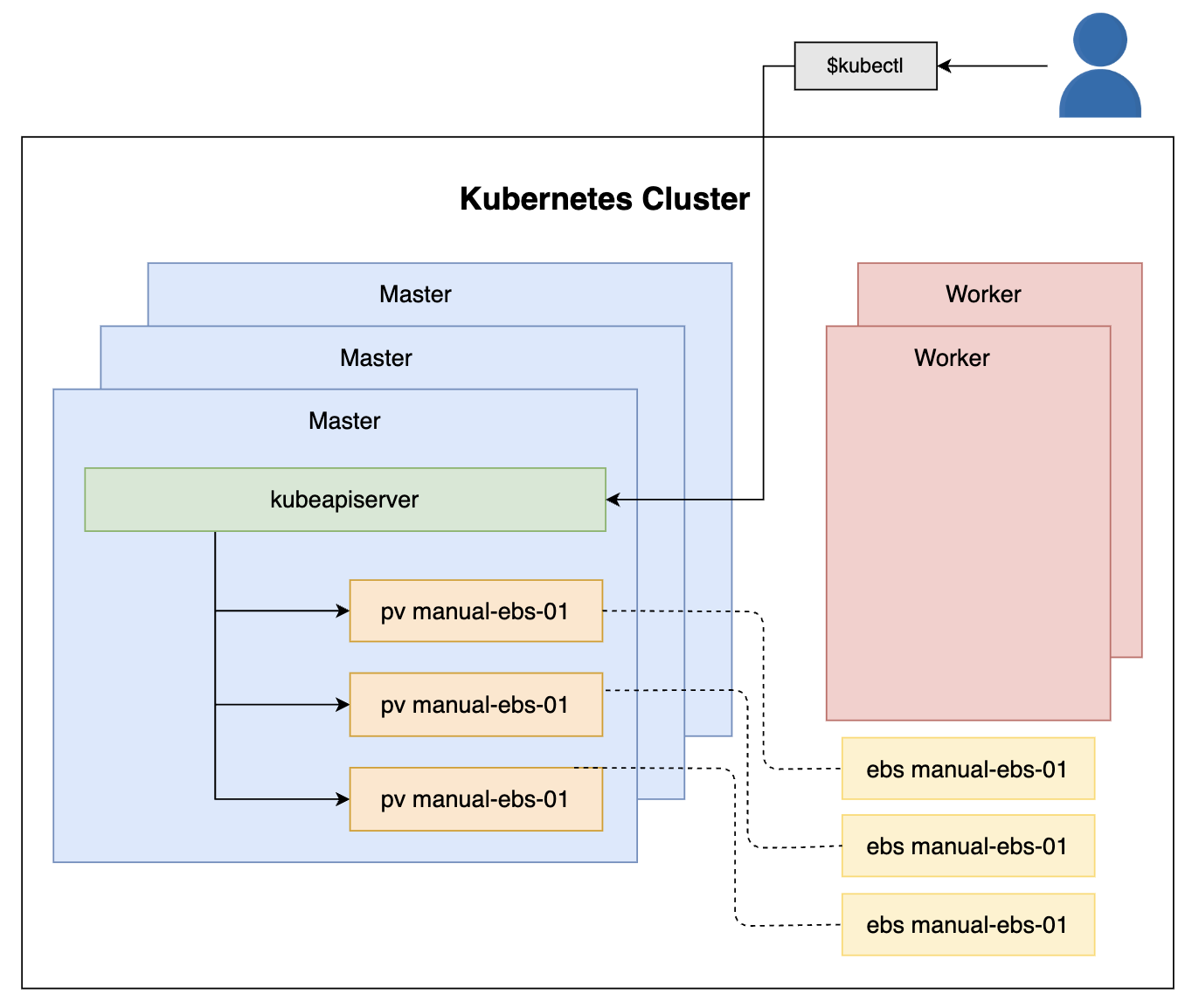
实践-声明持久卷
正如 Pod 不应该指定它们应该在哪个节点上运行一样,PersistentVolumeClaims 不能定义它们应该挂在哪一个卷。
Kubernetes 调度程序将根据申请的资源为他们分配一个卷。
cat pv/pvc.yml
pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: jenkins
namespace: jenkins
spec:
storageClassName: manual-ebs
accessMode:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
YAML 文件定义了一个存储类名称为 manual-ebs 的 PersistentVolumeClaim。这与我们之前创建的 PersistentVolumes manual-ebs-* 类相同。
我们没有指定我们想要使用的卷。相反,此声明指定了一组属性(storageClassName、accessModes 和 storage)。系统中与这些规范匹配的任何卷都可能由名为 jenkins 的 PersistentVolumeClaim 声明。
请记住, 资源不必完全匹配,具有相同或更大存储量的任何卷都被视为匹配项。
创建持久卷声明
kubectl create -f pv/pvc.yml \
--save-config --record
# Output: the persistentvolumeclaim "jenkins" is created
verify
kubectl --namespace jenkins \
get pvc

状态为 Bound,这意味着声明找到了一个匹配的持久卷。
注意: 如果 PersistentVolumeClaim 找不到匹配的卷,它将无限期地保持未绑定状态,除非我们添加具有匹配规范的新 PersistentVolume。
kubectl get pv

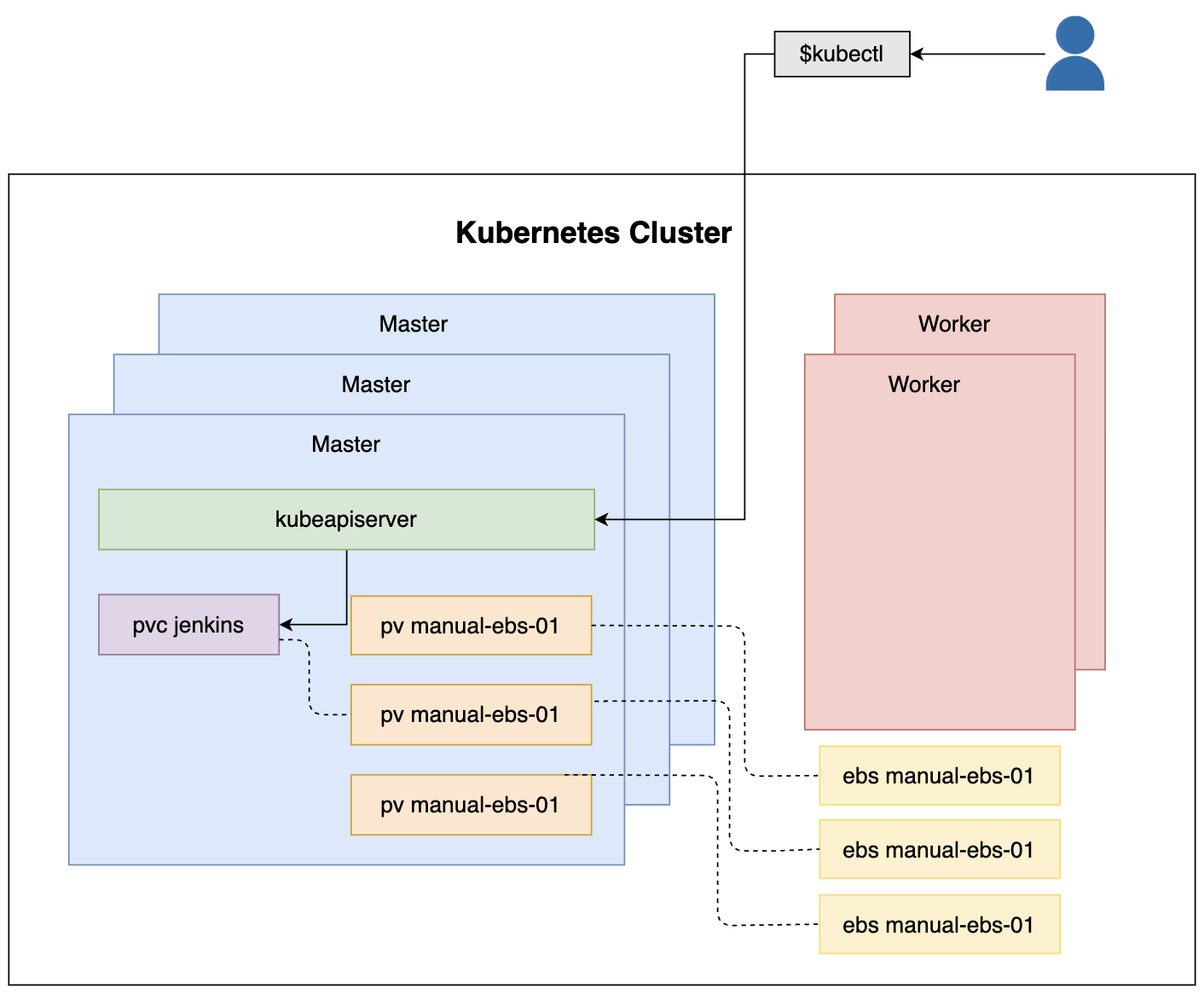
实践-创建用于将声明持久卷附加到 Pod 的 Deployment
定义 pv/jenkins-pv.yml
...
apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkins
namespace: jenkins
spec:
...
template:
...
spec:
containers:
- name: jenkins
...
volumeMounts:
- name: jenkins-home
mountPath: /var/jenkins_home
...
volumes:
- name: jenkins-home
persistentVolumeClaim:
claimName: jenkins
...
您会注意到,这一次,我们添加了一个新的卷 jenkins-home,它引用了名为 jenkins 的 PersistentVolumeClaim。从容器的角度来看,声明是一个卷。
部署资源
kubectl apply \
-f pv/jenkins-pv.yml \
--record

verify
等到 deployment 部署后,继续进行测试。
kubectl --namespace jenkins \
rollout status \
deployment jenkins
通过 Kubernetes API 创建 deployment,它包括 replicatSet,replicatSet 会创建 jenkins Pod。 它挂载了 PersistentVolumeClaim, 该声明绑定到 EBS 卷类型的 PersistentVolume 上。
因此,EBS 卷被挂载到 Pod 中运行的 Jenkins 容器中。
顺序分解
- 执行
kubectl命令 kubectl向kube-apiserver发送请求以创建pv/jenkins-pv.yml中定义的资源jenkinsPod 是在一个 worker 节点中创建的- 由于 Pod 中有持久卷声明 PersistentVolumClaim,因此它将挂载一个逻辑卷
- PersistentVolumeClaim 已绑定到一个 PersistentVolume
- PersistentVolume 与一个 AWS EBS 卷关联
- EBS 卷作为物理卷挂载到
jenkinsPod
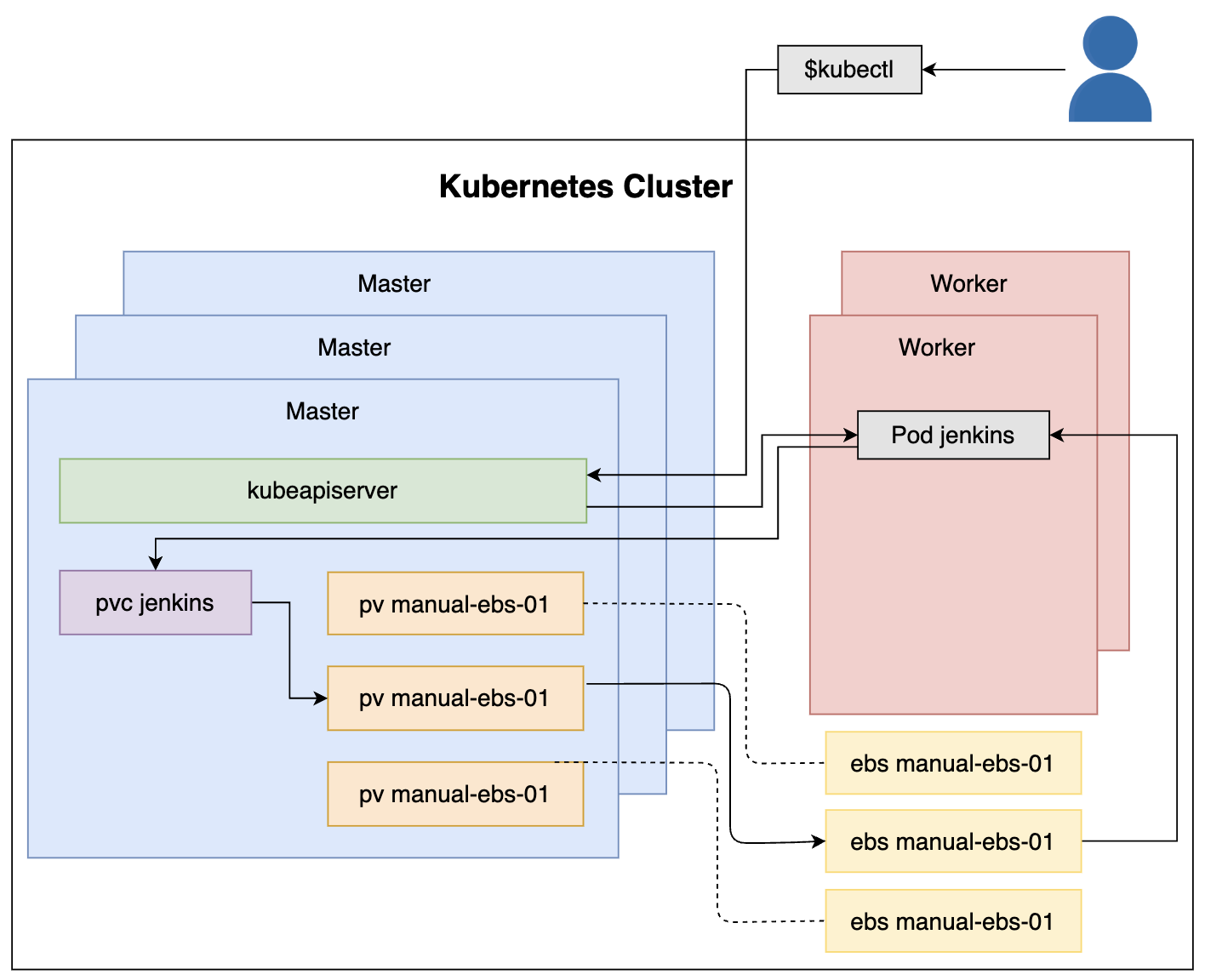
实践-检验持久性和故障
检验持久性
参考 实践-部署有状态应用(不持久化状态)。
检验状态持久性
open "http://$CLUSTER_DNS/jenkins"
创建任务: 使用之前的 Secret 登陆,并创建一个作业:"my-job" 项目,选择 "pipeline" 类型,确定,保存。
获取 Pod
POD_NAME=$(kubectl \
--namespace jenkins \
get pod \
--selector=app=jenkins \
-o jsonpath="{.items[*].metadata.name}")
终止进程
kubectl --namespace jenkins \
exec -it $POD_NAME pkill java
通过停止 java,导致 Jenkins 进程终止,模拟容器故障。因此,Kubernetes 检测到故障并重新创建容器。
verify
open "http://$CLUSTER_DNS/jenkins"
打开之后,我们检查状态是否被保留。如果作业依然可用,证明我们成功将 EBS 卷挂载为 Jenkins 保留其状态的目录。
节点故障
如果我们不是销毁容器,而是终止运行 Pod 的服务器,那么从功能的角度来看,结果将是相同的。
Pod 将被重新调度到运行状况良好的节点。Jenkins 将重新启动并从 EBS 卷恢复其状态。
由于 EBS 在无法跨服务区的原因,我们其中一个节点挂掉,并不会让 jenkins Pod 马上在另一个可用区的节点启动。
所以我们得等到当前可用区的节点重启启动后,再次启动 jenkins Pod 来保持之前的状态。另外我们有三个可用区,所以如果新的 EC2 实例在第三个新的可用区(概率为 50%,有一个节点已经在一个服务区,另外是二选一的情况),这个情况会比较尴尬。
节点故障-更多服务器,更多容错能力
在实际场景中,3 个可用区上分配 3 个节点会是更好的选择,Auto-Scaling 组会尝试在所有区域平均分配 EC2 实例,但不能保证会发生。工作节点最小的数量最好为 6。
我们拥有的服务器越多,集群具有容错能力的可能性就越高。如果我们托管有状态的应用程序,则尤其如此。
为了获得更多的容错能力,我们可以考虑将原本 3 个容量比较大的节点服务器换成 6 个容量比较小的节点服务器。
更多的节点意味着更多花费在维持 Kubernetes 系统 Pods 上花费更多的资源开销,但是我们认为通过他们获得更稳定的集群是值得的。
可用区故障
整个可用区(数据中心)可能会失败。Kubernetes 将继续正常工作。它将有两个而不是三个主节点运行,并且失败的工作节点将在运行状况良好的区域重新创建。
但是对于有状态的服务会比较麻烦,Kubernetes 无法将 EBS 挂载到另一个可用区域,只能够等待可用区重新上线,或我们手动将 EBS 卷移动到状况良好的区域。
解决方案:具体的方案因案例不同而不同
一,有没有可能构建流程,同步不同区域的 EBS 数据,但是为了实现同步会有更多花销,同时会影响到正常运行的性能。
二,使用 EFS 而不是 EBS。牺牲性能,Kubernetes 在当前已经支持 AWS EFS,换取跨可用区的持久卷。
注意: 总而言之,每种解决方案都有优点和缺点,没有一种解决方案适合所有用例。
实践-删除资源
kubectl --namespace jenkins delete \
deploy jenkins
# Output: the deployment "jenkins" is deleted
PersistentVolumeClaim 和 PersistentVolume 是否发生了什么变化?
kubectl --namespace jenkins get pvc
kubectl get pv

即使我们删除了 Jenkins Deployment 和使用持久卷声明的 Pod,PersistentVolumeClaim 和 PersistentVolumes 仍然完好无损。
删除 PersistentVolumeClaim
kubectl --namespace jenkins \
delete pvc jenkins
# Output: the persistentvolumclaim "jenkins" is deleted
kubectl get pv

manual-ebs-2 卷的状态为 Released。
定义-回收策略 Reclaim policy
该策略将在我们删除绑定到 manual-ebs-02 的 PersistentVolumeClaim 时应用。开始创建时,我们未指定 ReclaimPolicy,默认策略为 Retain。
Retain 回收策略
Retain 回收策略强制手动回收资源。删除声明后,PersistentVolume 仍然存在,且状态变为 Released。
但是它不可以用与其他持久卷声明,因为卷上还有原数据在。如果我们希望使用,需要先删除 EBS 卷上的所有数据。
其他回收策略
另外两个回收策略是Recycle (deprecated) 和 Delete。Delete 策略需要动态预置,稍后说明。
实践-删除资源
删除 Kuberntes persistentVolumes
kubectl delete -f pv/pv.yml

删除 AWS EBS
aws ec2 delete-volume \
--volume-id $VOLUME_ID_1
aws ec2 delete-volume \
--volume-id $VOLUME_ID_2
aws ec2 delete-volume \
--volume-id $VOLUME_ID_3
手动创建 PersistentVolume 的方式管理卷,集群管理员需要确保始终额外数量的可用卷供持久卷声明使用。
这是一项乏味的工作,通常会导致数据量超出我们的需求。
如果没有足够的可用卷,即使有声明,也会找不到适合的卷。
实践-使用存储类区动态配置的 PersistentVolumes
我们之前使用的都是静态 PersistentVolumes: 必须手动创建 EBS 卷和 Kubernetes PersistentVolumes。只有这两者可用后,才能部署通过 PersistentVolumeClaims 挂载卷的 Pod。
在某些情况下,预置的静态卷时必须的,我们的基础设施无法创建动态卷。尽管如此,我们通过一些工具,对流程做修改以及选择正确的卷类型,通常我们是可以达到动态卷的配置的。
而 AWS 能够做静态卷的设置,也支持做关于动态卷基础设施管理的。
注意: 只有在没有任何静态 PersistentVolume 与我们的声明匹配时,才会使用它。换句话说,Kubernetes 总是优先选择静态创建的 PersistentVolume 而非动态创建的。
动态卷配置允许我们按需创建存储。我们可以在资源请求时自动预置存储,而不是手动预置存储。
通过 storage.k8s.io API 组中的 StorageClasses 来启动动态供应,它允许我们描述可以申请的存储类型。
通过它,集群管理者可以创建于存储风格一样多的 StorageClasses, 集群用户也不必担心外部存储的可用信息。
StorageClasses
kubectl get sc

声明 PersistentVolume
cat pv/jenkins-dynamic.yml
...
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: jenkins
namespace: jenkins
spec:
storageClassName: gp2
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
...
与之前定义基本相同,唯一不同的是指定 StorageClassName 为gp2 ,以及我们没有预先创建 PersistentVolume。
创建资源
kubectl apply \
-f pv/jenkins-dynamic.yml \
--record
kubectl --namespace jenkins \
rollout status \
deployment jenkins
kubectl --namespace jenkins \
get events

verify
检查 pvc
kubectl --namespace jenkins get pvc

检查 pv
kubectl get pv

确认 EBS 卷
aws ec2 describe-volumes \
--filters 'Name=tag-key,Values="kubernetes.io/created-for/pvc/name"'
state --> in-use

删除资源
kubectl --namespace jenkins \
delete deploy,pvc jenkins

pv is deleted
kubectl get pv
# Output: no resources were found
aws EBS is deleted
aws ec2 describe-volumes \
--filters 'Name=tag-key,Values="kubernetes.io/created-for/pvc/name"'

动态配置不仅在资源声明卷时创建卷,也会在释放声明时删除卷。动态配置生成卷的回收策略是 Delete。
实践-自动指定默认 StorageClasses
DefaultStorageClass 准入控制器(比较高级的组件,会拦截 API 请求)会观察 PersistentVolumeClaims 的创建。通过它,那些不请求任何特定存储类的存储将自动分配一个默认存储类。因此,不请求任何特殊存储类的 PersistentVolumeClaims 将绑定到从默认 StorageClass 创建的 PersistentVolumes。
用户不必关系类别,除非他们有特俗的类别需求;如果没有指定特殊类型的卷,默认 StorageClass 将会作为输入值。
可用的 StorageClasses
kubectl get sc

kubectl describe sc gp2
Terminal
Name: gp2
IsDefaultClass: Yes
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{"storageclass.beta.kubernetes.io/is-default-class":"true"},"labels":{"k8s-addon":"storage-aws.addons.k8s.io"},"name":"gp2","namespace":""},"parameters":{"type":"gp2"},"provisioner":"kubernetes.io/aws-ebs"}
,storageclass.beta.kubernetes.io/is-default-class=true
Provisioner: kubernetes.io/aws-ebs
Parameters: type=gp2
ReclaimPolicy: Delete
Events: <none>
注意 "storageclass.beta.kubernetes.io/is-default-class":"true",它将 StorageClass 设置为 default。
调用 jenkins
cat pv/jenkins-default.yml
...
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: jenkins
namespace: jenkins
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
...
diff pv/jenkins-dynamic.yml \
pv/jenkins-default.yml
区别在于未定义 storageClassName。

apply
kubectl apply \
-f pv/jenkins-default.yml \
--record

验证 PersistentVolumes
kubectl get pv
我们没有指定 stoageClass,也会基于 gp2 创建一个卷,也是默认类。

删除资源
kubectl --namespace jenkins \
delete deploy,pvc jenkins

实践-定义存储类
用户定义的存储类
比如,我们希望为 Jenkins 创建 io1 类型的 EBS 卷。
cat pv/sc.yml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast
labels:
type: ebs
provisioner: kubernetes.io/aws-ebs
parameters:
type: type: io1 # https://aws.amazon.com/ebs/details/ > Amazon EBS Volume Types
reclaimPolicy: Delete
使用 kubernetes.io/aws-ebs 作为预置程序。它是必填的,为预置 PersistentVolumes 的服务提供的插件。
支持的 Provisioner 列表
| Volume Plugin | Internal Provisioner |
|---|---|
| AWSElasticBlockStore | Yes |
| AzureFile | Yes |
| AzureDisk | yes |
| CephFS | No |
| Cinder | Yes |
| FC | No |
| FlexVolume | No |
| Flocker | Yes |
| GCEPersistentDisk | Yes |
| Glusterfs | Yes |
| iSCSI | No |
| PhotonPersistentDisk | Yes |
| Quobyte | Yes |
| NFS | No |
| RBD | Yes |
| VsphereVolume | Yes |
| PortworxVolume | Yes |
| ScaleIO | Yes |
| StorageOS | Yes |
| Local | No |
- 内部 Provisioning 是名称前缀为
kubernetes.io的 Provisioner(例如kubernetes.io/aws-ebs)。它们随 Kubernetes 一起提供。 - 外部供应程序是独立于 Kubernetes 提供的独立程序。NFS 是常用的外部供应程序的例子。
参数取决于 StorageClass,我们使用 aws-ebs,我们可以指定的参数之一是 type,它可以是:
- EBS Provisioned IOPS SSD (
io1),我们指定io1,这时性能最高的卷 - EBS General Purpose SSD (
gp2) - Throughput Optimized HDD (
st1) - Cold HDD (
sc1)
回收策略
最后,我们将reclaimPolicy设置为Delete。与Retain不同,后者要求我们在释放的卷可供新的 PersistentVolumeClaim 使用之前删除其内容,而 Delete 则会同时移除 PersistentVolume 及外部架构中的关联卷。
Delete 回收策略仅适用于部分外部卷,如 AWS EBS、Azure Disk 或 Cinder 卷。
实践-创建存储类
kubectl create -f pv/sc.yml
# Output: the `storageclass "fast"` was `created`
verify
kubectl get sc

创建 Deployment
cat pv/jenkins-sc.yml
...
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: jenkins
namespace: jenkins
spec:
storageClassName: fast
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
...
应用 storageClassName: fast:
kubectl apply \
-f pv/jenkins-sc.yml \
--record

verify
aws ec2 describe-volumes \
--filters 'Name=tag-key,Values="kubernetes.io/created-for/pvc/name"'

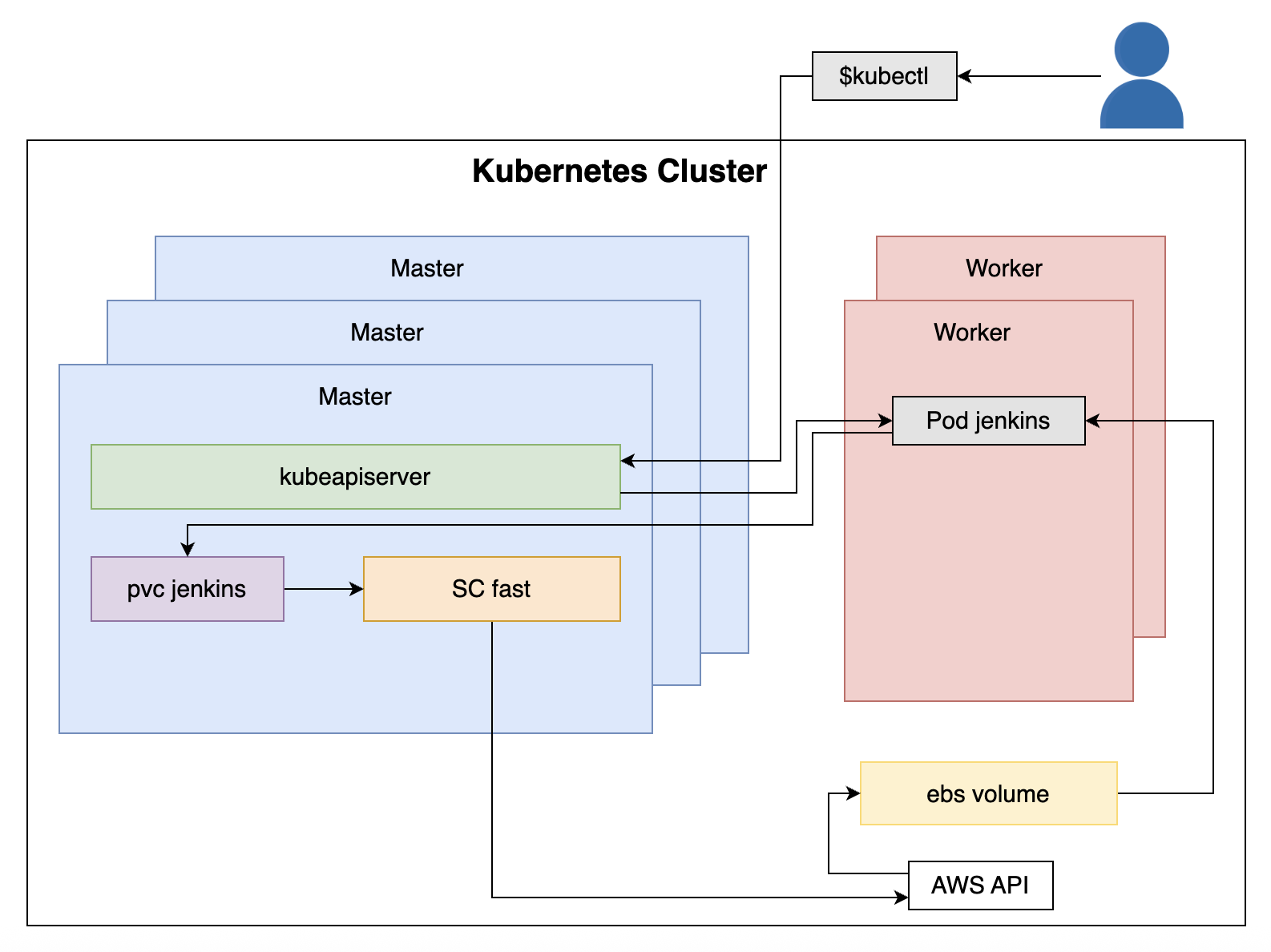
- 创建
jenkinsDeployment, 它创建 ReplicaSet 以及 对应的 Pod - Pod 通过 PersistentVolumeClaim 请求持久化存储
- PersistentVolumeClaim 请求具有名为
fast的 StorageClass 的 PersistentStorage - StorageClass
fast被确定为创建新的 EBS 卷,它向 AWS API 发送请求出创建 EBS 卷 - AWS API 创建 EBS 卷
- EBS 卷挂载到
jenkinsPod
测试后,删除卷和集群即可。
kubectl delete ns jenkins
kops delete cluster \
--name $NAME \
--yes
aws s3api delete-bucket \
--bucket $BUCKET_NAME