实践-利用 GitHub 生态系统进行开发-训练模型
· 8 min read
关键术语
- Codespaces- 由 GitHub 托管的基于云的一次性开发环境。提供可重现性和自定义功能。
- 可重复性--可靠地重新创建环境并获得相同结果的能力。代码空间通过容器确保了这一点。
- 容器映像(Container Image)- 一种轻量级、独立、可执行的软件包,允许代码跨环境快速、可靠地运行。
- GPU- 利用专用硬件加速机器学习模型构建/训练的图形处理单元。
- Copilot- GitHub 的人工智能配对程序员,可在开发人员输入代码时向其推荐代码和整个函数。
- 持续集成(Continuous Integration)- 通过自动构建和测试流程,频繁合并代码变更并验证每项变更的开发实践。
- 持续交付(Continuous Delivery)--软件方法论,团队可通过自动部署快速、可靠、可持续地向用户发布新变更。
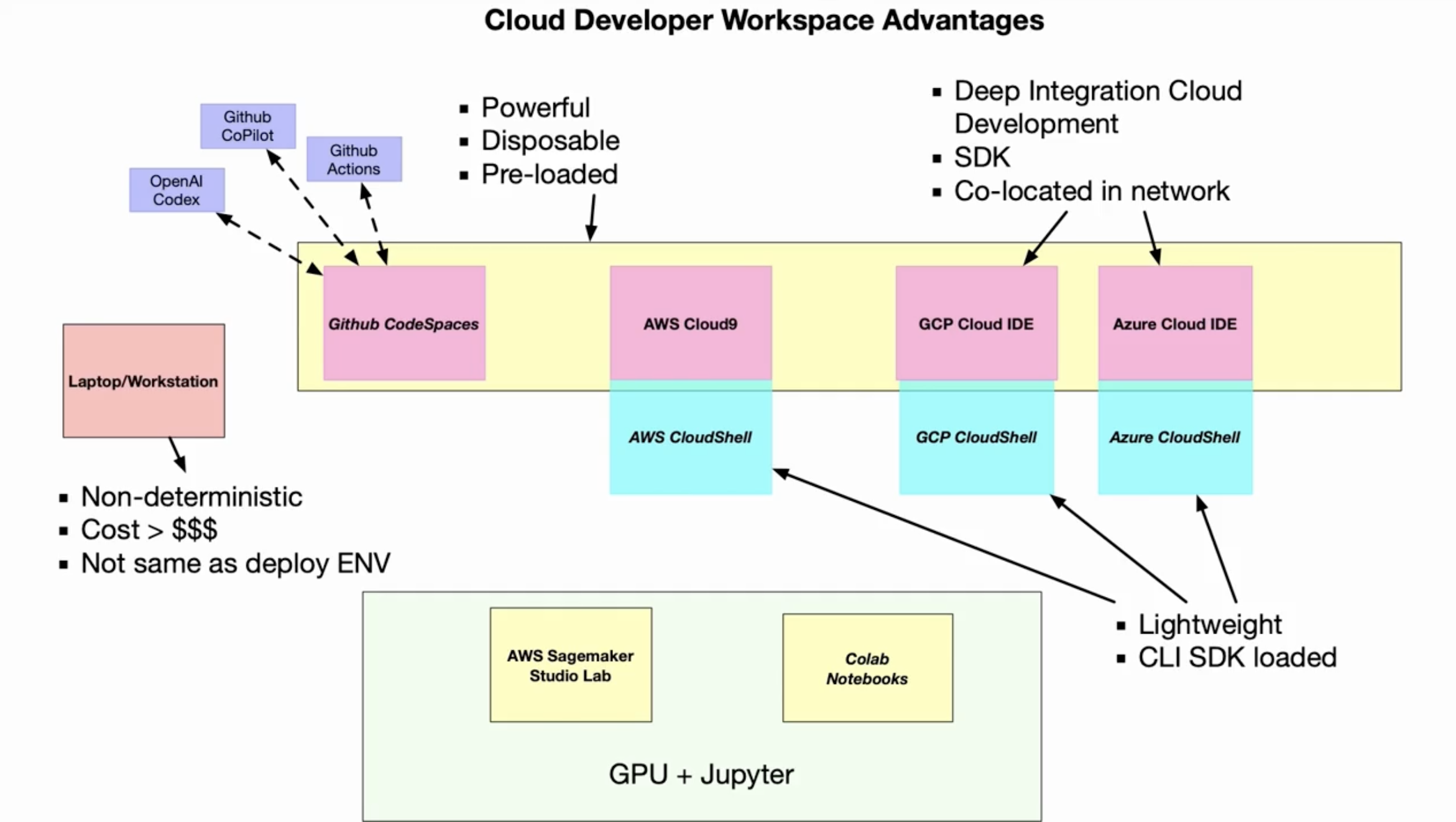
云开发人员工作区
SSD: Solid State Drive
GitHub 生态系统的关键组成
- Reproducibility: Codespaces
- Access to GPU: Machine Learning Codespaces
- AI Coding Assistant: Copilot
- Continuous Integration & Deploy: GitHub Actions
Reproducibility With Codespaces
- CLoud-based development Workspace)
- Container Image
- Configuration
- Compute & Storage
Access to GPU
- HuggingFace
- PyTorch
- TensorFlow
- Nvidia Cuda
AI Coding Assitant
- Copilot Feedback Loop
- Prompt
- Format
- Execute
- Lint
- Test
Continuous Integration & Deploy
- Codespace
- make install
- make test
- make deploy
- GitHub Actions
- Amazon ECR
- App Runner
- FastAPI
使用 GitHub 模板
- mlops-template: https://github.com/nogibjj/mlops-template
- xiaokatech/hugging-face-cli-with-codespaces: https://github.com/xiaokatech/hugging-face-cli-with-codespaces
Fine-Tuning with Hugging Face
Definition
在 Github Codespace 中对 Hugging Face 的模型做微调。
pip install --upgrade pip
pip isntall -r requirements.txt
- 目的:这段代码使用 BERT 模型在 Yelp 评论数据集上进行微调,实现一个文本分类任务(预测评论的星级 1-5)。
- 主要步骤:
- 加载 Yelp 评论数据集(
yelp_review_full) - 使用 BERT 的分词器(tokenizer)对文本进行预处理
- 加载预训练的 BERT 模型(
bert-base-cased)并调整为 5 分类任务 - 设置训练参数和评估指标(准确率)
- 进行模型训练
- 加载 Yelp 评论数据集(
- 关键组件:
AutoTokenizer: 用于文本分词和编码AutoModelForSequenceClassification: 预训练模型,调整为分类任务TrainingArguments: 定义训练参数(如输出目录、评估策略等)Trainer: 简化训练流程的高级 API
- 训练数据:
- 使用的是完整的 Yelp 评论数据集(约 650,000 条训练样本)
- 代码中注释掉的部分展示了如何用少量样本(1000 条)进行快速测试
- 评估方式:
- 每个 epoch 结束后在测试集上评估
- 使用准确率(accuracy)作为评估指标
- 最后一行
trainer.train():- 这是实际开始模型训练的命令
- 会根据设置的参数进行多轮(epoch)训练
- 每轮结束后会显示训练损失和评估指标
Dependencies
requirements.txt
#tensorflow==2.9.1
beautifulsoup4==4.11.1
wikipedia==1.4.0
pylint==2.15.0
pytest
gradio
sentencepiece
black
click
transformers
datasets
scikit-learn
git+https://github.com/openai/whisper.git
newspaper3k
ipdb
git+https://github.com/LIAAD/yake
# pytorch and cuda are installed/listed on environment.yml
evaluate
accelerate
hugging-face-cli-with-codespaces: https://github.com/nogibjj/hugging-face-cli-with-codespaces
With Whole Dataset
fineTuningExample/ftHelloWorld.py
这个代码用的是全部数据来训练,会非常久。
#!/usr/bin/env python
"""
Fine Tuning Example with HuggingFace
Based on official tutorial
"""
from transformers import AutoTokenizer
from datasets import load_dataset
import evaluate
from transformers import AutoModelForSequenceClassification
from transformers import TrainingArguments, Trainer
import numpy as np
# Load the dataset
dataset = load_dataset("yelp_review_full")
dataset["train"][100]
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Load the model
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# can use if needed to reduce memory usage and training time
#small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
#small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
training_args = TrainingArguments(output_dir="test_trainer")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
compute_metrics=compute_metrics,
)
trainer.train() # train the model
With Small Dataset
fineTuningExample/ftHelloWorld_small_dataset.py
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
#!/usr/bin/env python
"""
Fine Tuning Example with HuggingFace
Based on official tutorial
"""
from transformers import AutoTokenizer
from datasets import load_dataset
import evaluate
from transformers import AutoModelForSequenceClassification
from transformers import TrainingArguments, Trainer
import numpy as np
# Load the dataset
dataset = load_dataset("yelp_review_full")
dataset["train"][100]
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Load the model
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 只用1000条训练和测试数据进行实验,加快训练速度
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
training_args = TrainingArguments(output_dir="test_trainer")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train() # train the model

训练结果 test_trainer/checkpoint-39

文件夹 test_trainer 是 HuggingFace Trainer 的输出目录,里面通常包含以下内容:
config.json:训练参数和配置信息。pytorch_model.bin:保存的模型权重。trainer_state.json:训练进度、历史、超参数等状态信息。training_args.bin:序列化的 TrainingArguments。checkpoint-*文件夹:每个保存点的模型和优化器状态(如checkpoint-500)。runs/:TensorBoard 日志目录(如果启用)。eval_results.txt:评估结果(如果有评估)。
这些文件和文件夹用于模型恢复、推理、继续训练和分析训练过程。实际内容会根据训练参数和保存频率有所不同。
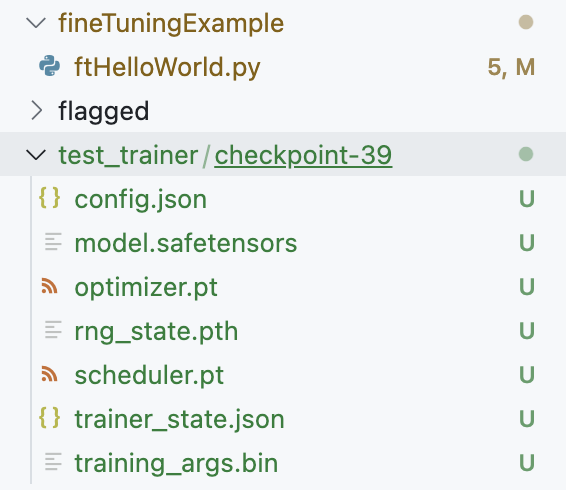
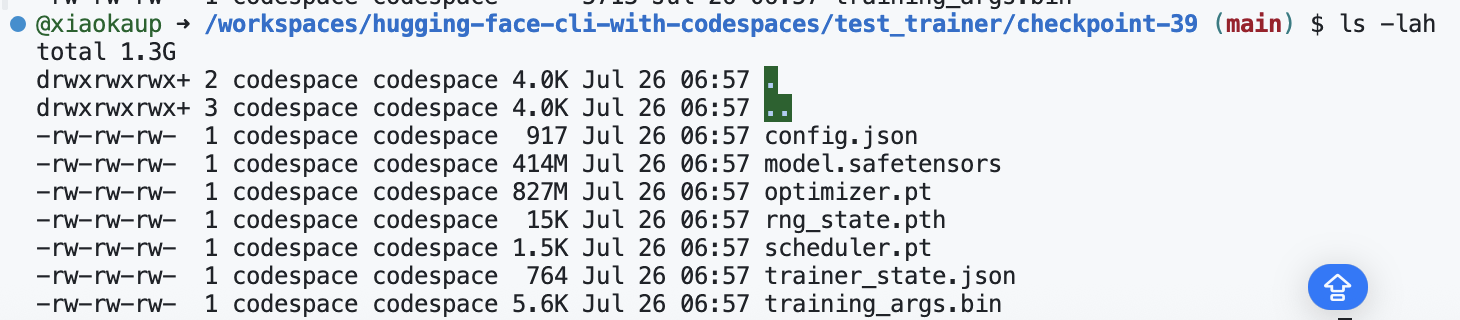
文件夹 test_trainer/checkpoint-39是训练过程中的一个模型检查点,里面的文件及作用如下:
config.json:模型结构和超参数的配置信息。model.safetensors:保存了当前 epoch/step 的模型权重(参数),用于后续加载和推理。文件很大是因为 BERT 这类模型参数量非常多,通常有上亿参数。optimizer.pt:保存优化器(如 Adam)的状态,包括动量等信息,用于断点续训。scheduler.pt:保存学习率调度器的状态。rng_state.pth:保存随机数生成器的状态,保证恢复训练时结果可复现。trainer_state.json:Trainer 的训练进度、历史、评估结果等信息。training_args.bin:序列化的训练参数(TrainingArguments)。
为什么 .pt 和 .safetensors 文件很大?
- 这些文件存储了整个神经网络的权重(即所有参数),BERT-base 这种模型通常有 1 亿多个参数,每个参数都是 32 位浮点数(4 字节),所以文件会很大(几百 MB 甚至更大)。
.safetensors是一种安全高效的权重存储格式,.pt是 PyTorch 的权重/状态保存格式。
这些文件让你可以随时恢复训练、做推理或迁移学习,无需重新训练整个模型。
使用训练模型预测
ftHelloWold_predict.py
#!/usr/bin/env python
"""
BERT Yelp Review 分类模型推理脚本
"""
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 加载模型和分词器
model = AutoModelForSequenceClassification.from_pretrained("test_trainer/checkpoint-39")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# 推理函数
def predict(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
predict_result = outputs.logits.argmax(dim=-1).item()
return predict_result
if __name__ == "__main__":
# 示例文本
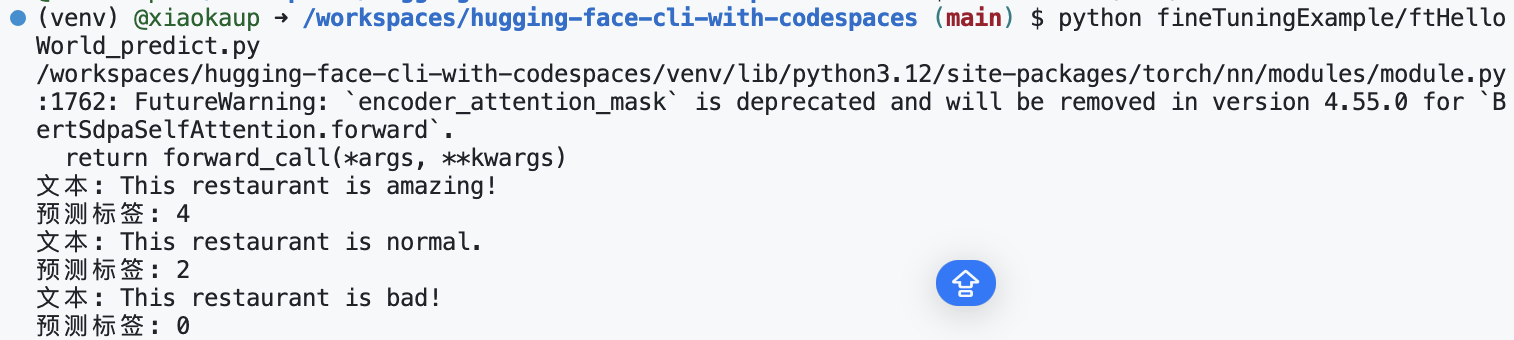
test_text = "This restaurant is amazing!"
label = predict(test_text)
print(f"文本: {test_text}\n预测标签: {label}")
test_text = "This restaurant is normal."
label = predict(test_text)
print(f"文本: {test_text}\n预测标签: {label}")
由于使用的数据量很小,结果没有那么准确。
训练量为 100 的效果

训练量为 1000 的效果
使用 click 给 .py 做成 cli 指令
calc.py
#/usr/bin/env python
"""
This module is used to create calculations functions such as addition, subtraction, multiplication, and division.
This module will also be invoked as a command line script using click.
"""
import click
def add(a, b):
"""
This function adds two numbers
"""
return a + b
def subtract(a, b):
"""
This function subtracts two numbers
"""
return a - b
def multiply(a, b):
"""
This function multiply two numbers
"""
return a * b
def divide(a, b):
"""
This function divide two numbers
"""
return a / b
# Build a click group
@click.group()
def cli():
"""
This is a calculator app
"""
pass
# Build a click command
@cli.command("add")
@click.argument('a', type=int)
@click.argument('b', type=int)
def add_command(a, b):
"""
This funciton adds two numbers
"""
click.echo(click.style(str(add(a, b)), fg='green'))
# Build a click command
@cli.command("subtract")
@click.argument('a', type=int)
@click.argument('b', type=int)
def subtract_command(a, b):
"""
This funciton subtracts two numbers
"""
click.echo(click.style(str(subtract(a, b)), fg='red'))
# Other commands
# ...
if __name__ == "__main__":
cli()