Kubernetes 理论与实践-5-搭建生产环境集群-kOps, AWS
前文回顾
- 资源分配
- 服务质量合同 QoS (Quality of Service)
- 命名空间中的资源默认值和限制, 配额 ResourceQuota
Context
Kubernetes Operations (KOps)
- KOps 是我们启动并运行生产级 Kubernetes 集群最简单的方式。(排除 GKE Google Kubernetes Engine 时)
- 完全开源,可以存储在版本口控制中,并且不会将我们锁定在供应商中。
供应商选择: AWS, 这是世界上最多人的选择。
Terraform: 使用它方便的一键增加删减资源。
常见生产环境实践,建议重点关注以下环境变量配置:
-
核心认证配置:
- AWS_ACCESS_KEY_ID / AWS_SECRET_ACCESS_KEY
- AWS_DEFAULT_REGION (集群目标区域)
- KOPS_STATE_STORE (s3://your-state-store)
-
集群网络配置:
- KOPS_CLUSTER_NAME (完整域名格式)
- KOPS_DNS_ZONE (Route53 托管区域)
- KOPS_NETWORKING (网络插件选择)
-
高级配置示例: export KOPS_FEATURE_FLAGS=+SpecOverrideFlag export KOPS_RUN_OBSOLETE_VERSION=y
实践-AWS 准备
- AWS 账户凭证
- 下载 aws-cli
实践-IAM 权限设置
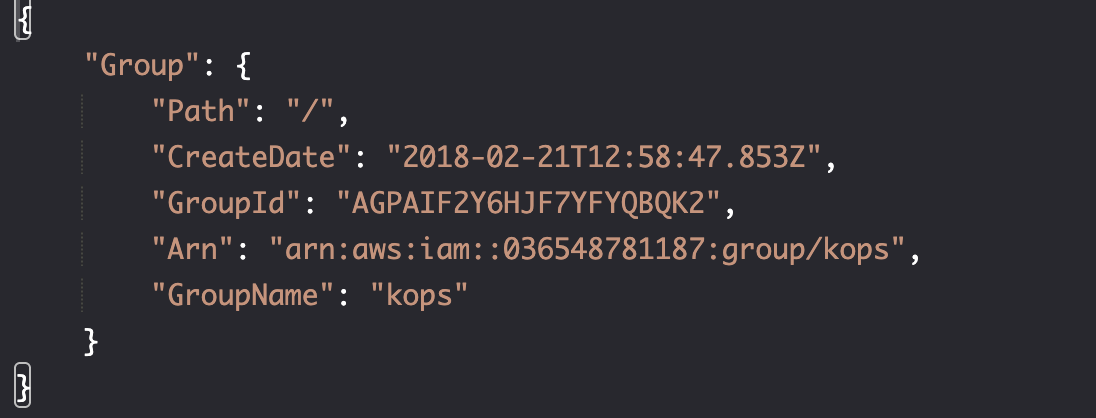
创建 iam group
aws iam create-group \ --group-name kops
resource "aws_iam_group" "kops_group" {
name = "kops"
path = "/"
}
添加权限
- AmazonEC2FullAccess: 集群由 EC2 组成,因此需要具有处啊过年就爱你和管理节点的权限。
- AmazonS3FullAccess: 需要 S3 来存储集群状态。
- AmazonVPCFullAccess: 需要 VPC 来隔离集群。
- IAMFullAccess: 创建其他 IAM。
aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess \
--group-name kops
aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess \
--group-name kops
aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonVPCFullAccess \
--group-name kops
aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/IAMFullAccess \
--group-name kops
resource "aws_iam_group_policy_attachment" "ec2_full_access" {
group = aws_iam_group.kops_group.name
policy_arn = "arn:aws:iam::aws:policy/AmazonEC2FullAccess"
}
resource "aws_iam_group_policy_attachment" "s3_full_access" {
group = aws_iam_group.kops_group.name
policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess"
}
resource "aws_iam_group_policy_attachment" "vpc_full_access" {
group = aws_iam_group.kops_group.name
policy_arn = "arn:aws:iam::aws:policy/AmazonVPCFullAccess"
}
resource "aws_iam_group_policy_attachment" "iam_full_access" {
group = aws_iam_group.kops_group.name
policy_arn = "arn:aws:iam::aws:policy/IAMFullAccess"
}
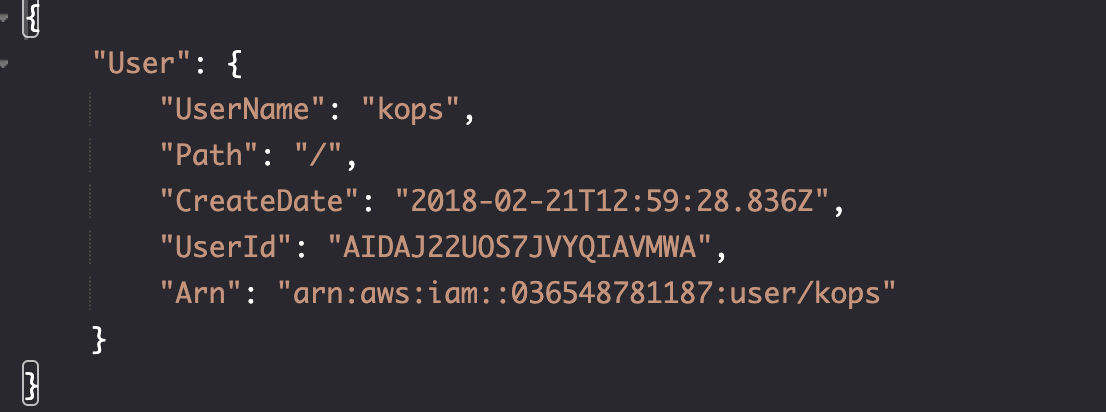
创建用户
aws iam create-user \
--user-name kops
resource "aws_iam_user" "example_user" {
name = "example-user" # Replace with your desired username
path = "/"
tags = {
Description = "Example IAM user"
Environment = "Development"
}
}
attach user and group
aws iam add-user-to-group \
--user-name kops \
--group-name kops
resource "aws_iam_user_group_membership" "kops_kops" {
user = aws_iam_user.kops.name
groups = [
aws_iam_group.kops.name
]
}
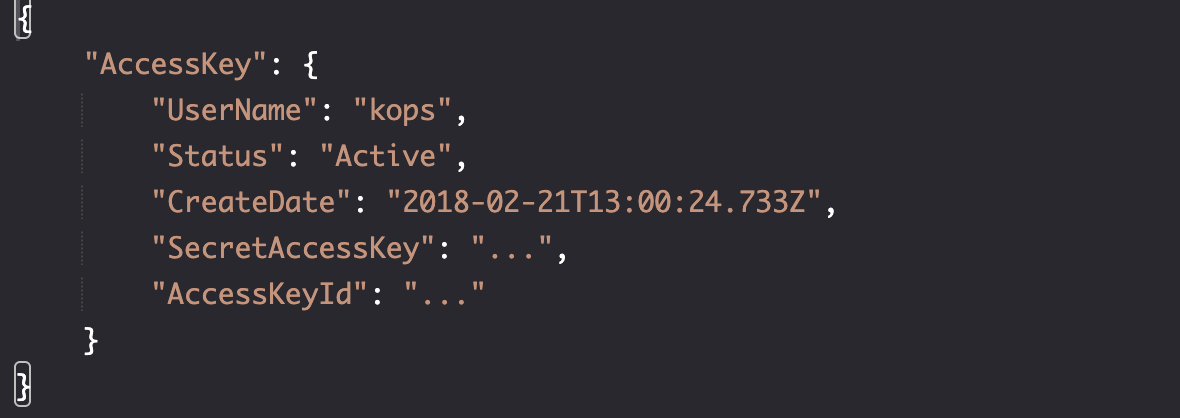
Create user access key
aws iam create-access-key \
--user-name kops >kops-creds
cat kops-creds
resource "aws_iam_access_key" "kops" {
user = "kops"
}
output "kops_access_key" {
value = aws_iam_access_key.kops.id
sensitive = true
}
output "kops_secret_key" {
value = aws_iam_access_key.kops.secret
sensitive = true
}
实践-可用区和 SSH 密匙
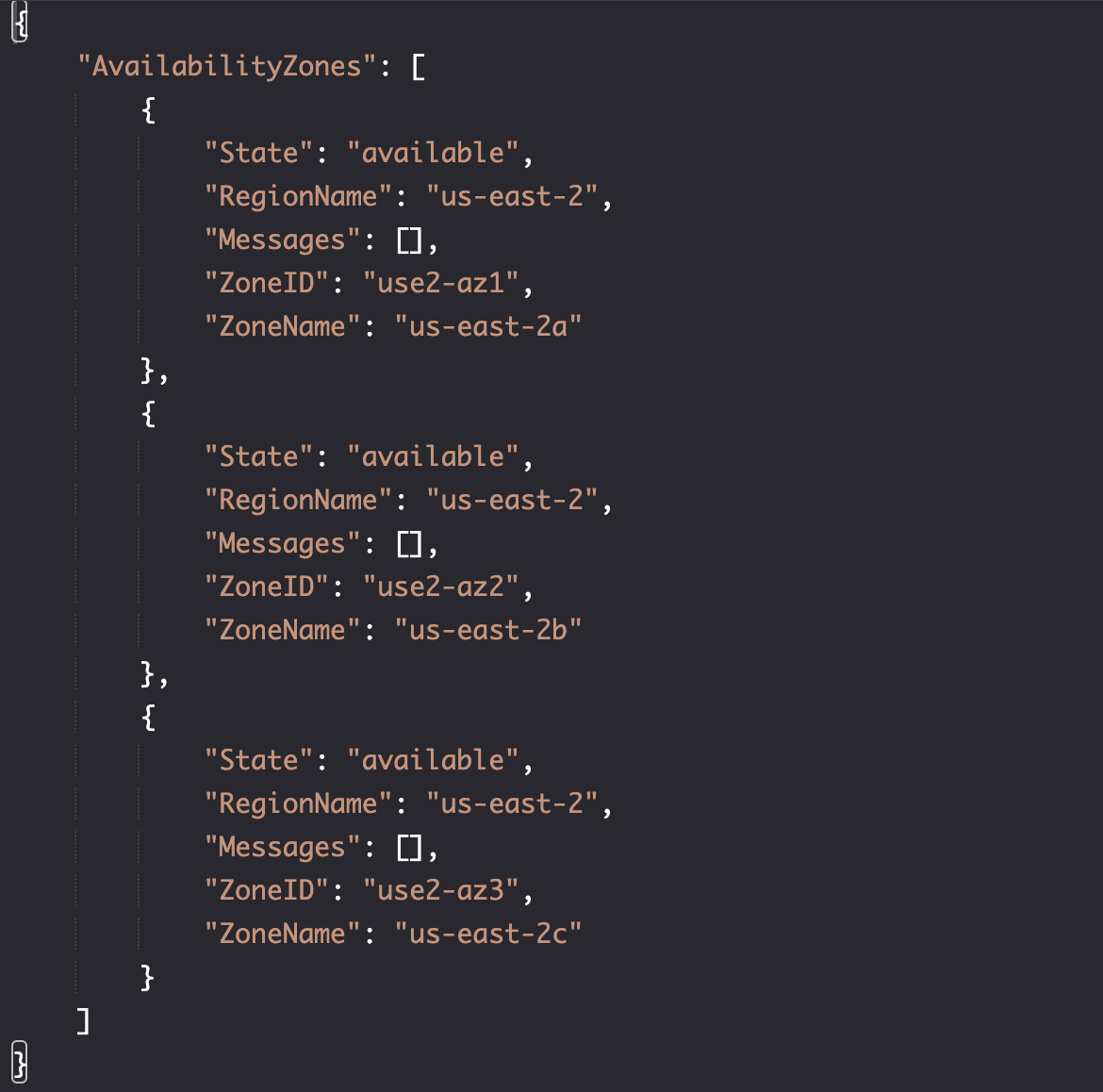
设置可用区
aws ec2 describe-availability-zones \
--region $AWS_DEFAULT_REGION
data "aws_availability_zones" "available" {
state = "available"
}
output "available_zones" {
value = data.aws_availability_zones.available.names
}
创建 SSH 密匙
aws ec2 create-key-pair \
--key-name devops23 \
| jq -r '.KeyMaterial' \
>devops23.pem
ssh-keygen -y -f devops23.pem \
>devops23.pub
# Genrate new keys
resource "tls_private_key" "devops23" {
algorithm = "RSA"
rsa_bits = 4096
}
# Save private key to file (equivalent to your original .pem file)
resource "local_file" "devops23_private_key" {
content = tls_private_key.devops23.private_key_pem
filename = "devops23.pem"
file_permission = "0400" # Restrictive permissions
}
# Save public key to file (equivalent to your ssh-keygen command)
resource "local_file" "devops23_public_key" {
content = tls_private_key.devops23.public_key_openssh
filename = "devops23.pub"
file_permission = "0644" # Standard permissions for public key
}
# Create AWS key pair
resource "aws_key_pair" "devops23" {
key_name = "devops23"
public_key = tls_private_key.devops23.public_key_openssh
}
创建 S3 bucekt
export BUCKET_NAME=devops23-$(date +%s)
aws s3api create-bucket \
--bucket $BUCKET_NAME \
--create-bucket-configuration \
LocationConstraint=$AWS_DEFAULT_REGION
export KOPS_STATE_STORE=s3://$BUCKET_NAME
resource "aws_s3_bucket" "example" {
bucket = "devops23-kubernetes-demo-s3-bucket"
tags = var.tags
}

install KOps
brew update && brew install kops
问题-创建集群: 规范
主节点数量
我们选择 3 个保证,每个主节点的可用性,避免出现一个主节点瘫痪后集群(2 个主节点)无法完成 quorum 程序,我们选择 3 个。
数据中心
为了避免数据中心瘫痪,我们和主节点一样,选择三个数据中心,并且保证 3 个数据中心较近,以避免延迟过高。
联网
- Kubenet
- CNI
- classic 经典 (x)
- external 外部 (x)
Classic Kubernetes 原生网络已放弃,外部网络用语自定义实现和特定用例,放弃。
CNI 接口有众多第三方插件可选择: Calico, flannel, Canak(Flannel + Calico), kopeio-vxlan, kube-router, romana, weave, and amazon-vpc-routed-eni,提供灵活性。
Kubenet 是 kOps 默认网络解决方案。它是原生网络,经过实战测试且非常可靠。不过有一条限制,即它只能管理最多具有 50 个节点的集群,受限于 AWS VPC 路由表配置数量。
节点大小
t2.small,选择最小节点。
实践-创建集群并验证
创建
export NAME=devops23.k8s.local
kops create cluster \
--name $NAME \
--master-count 3 \
--node-count 1 \
--node-size t2.small \
--master-size t2.small \
--zones $ZONES \
--master-zones $ZONES \
--ssh-public-key devops23.pub \
--networking kubenet \
--kubernetes-version v1.14.8 \
--yes
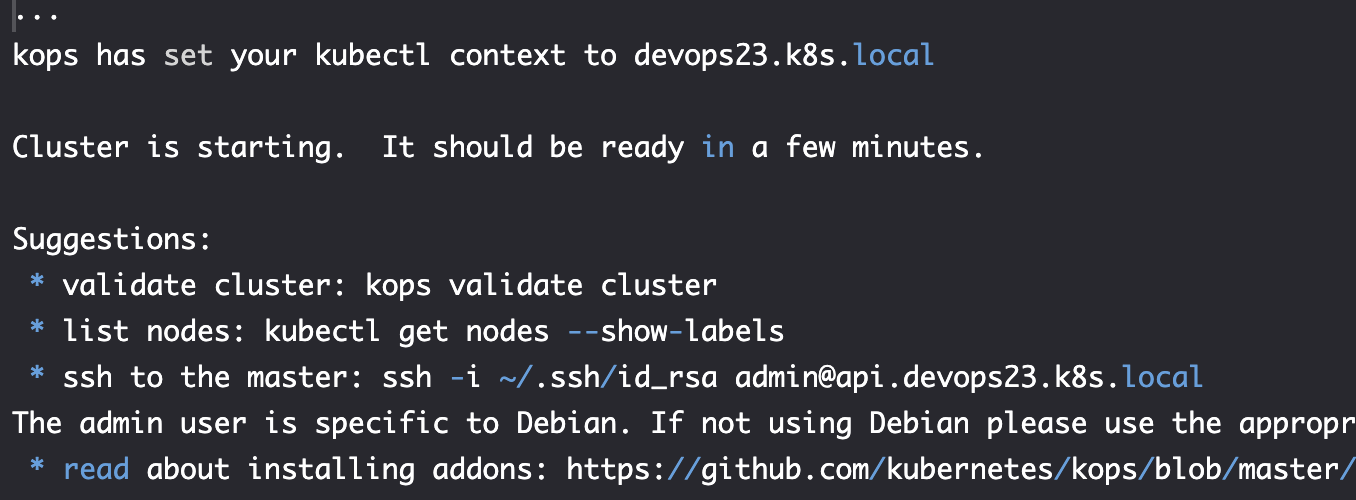
验证
kops get cluster

kubectl cluster-info

kops validate cluster
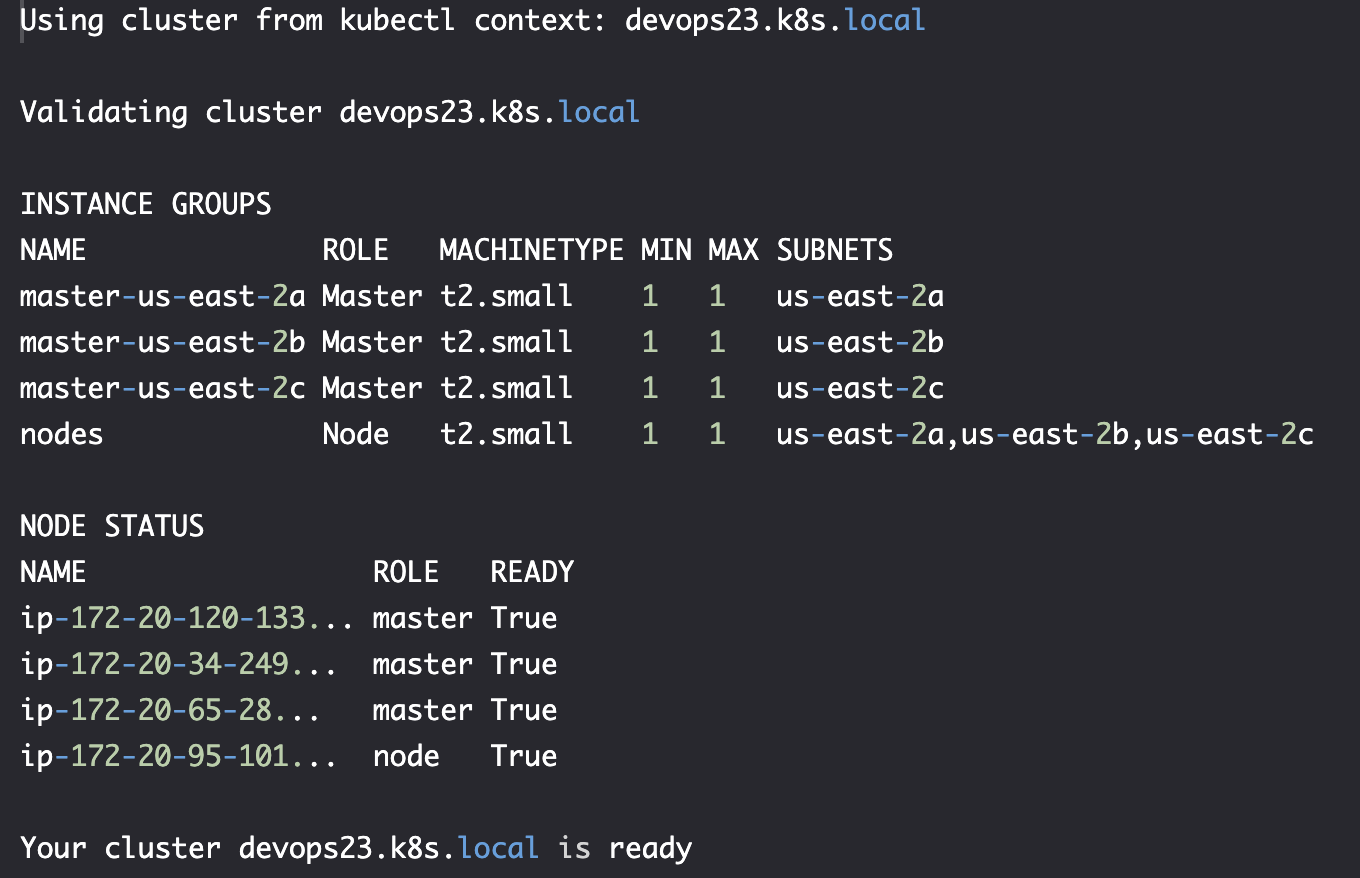
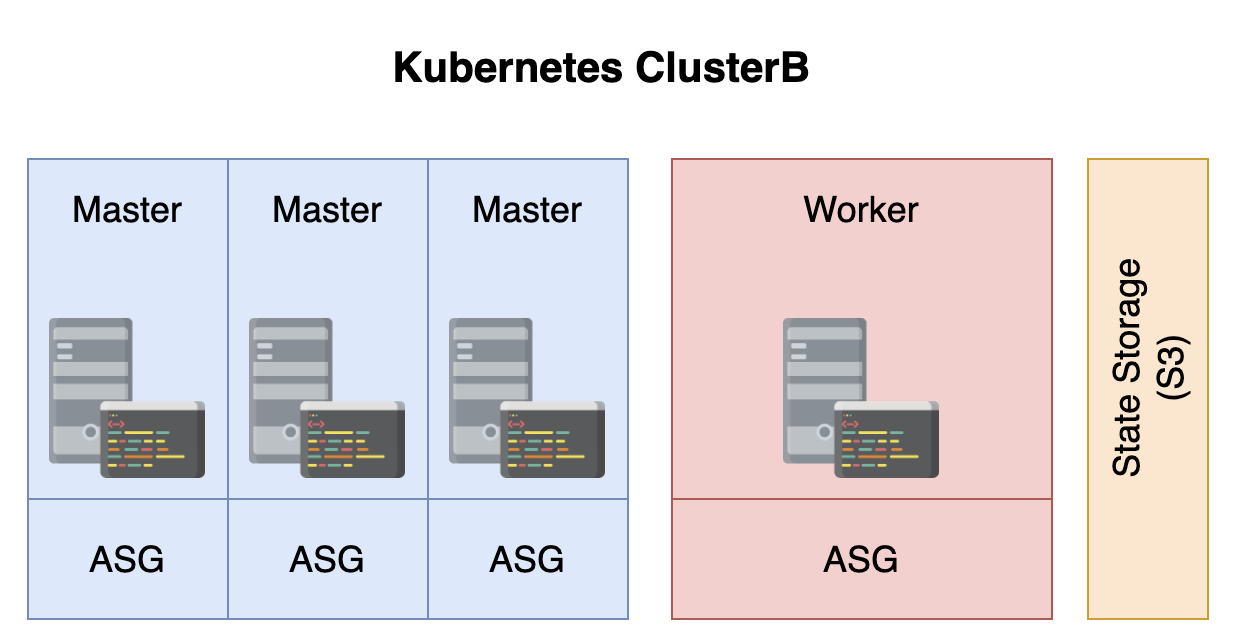
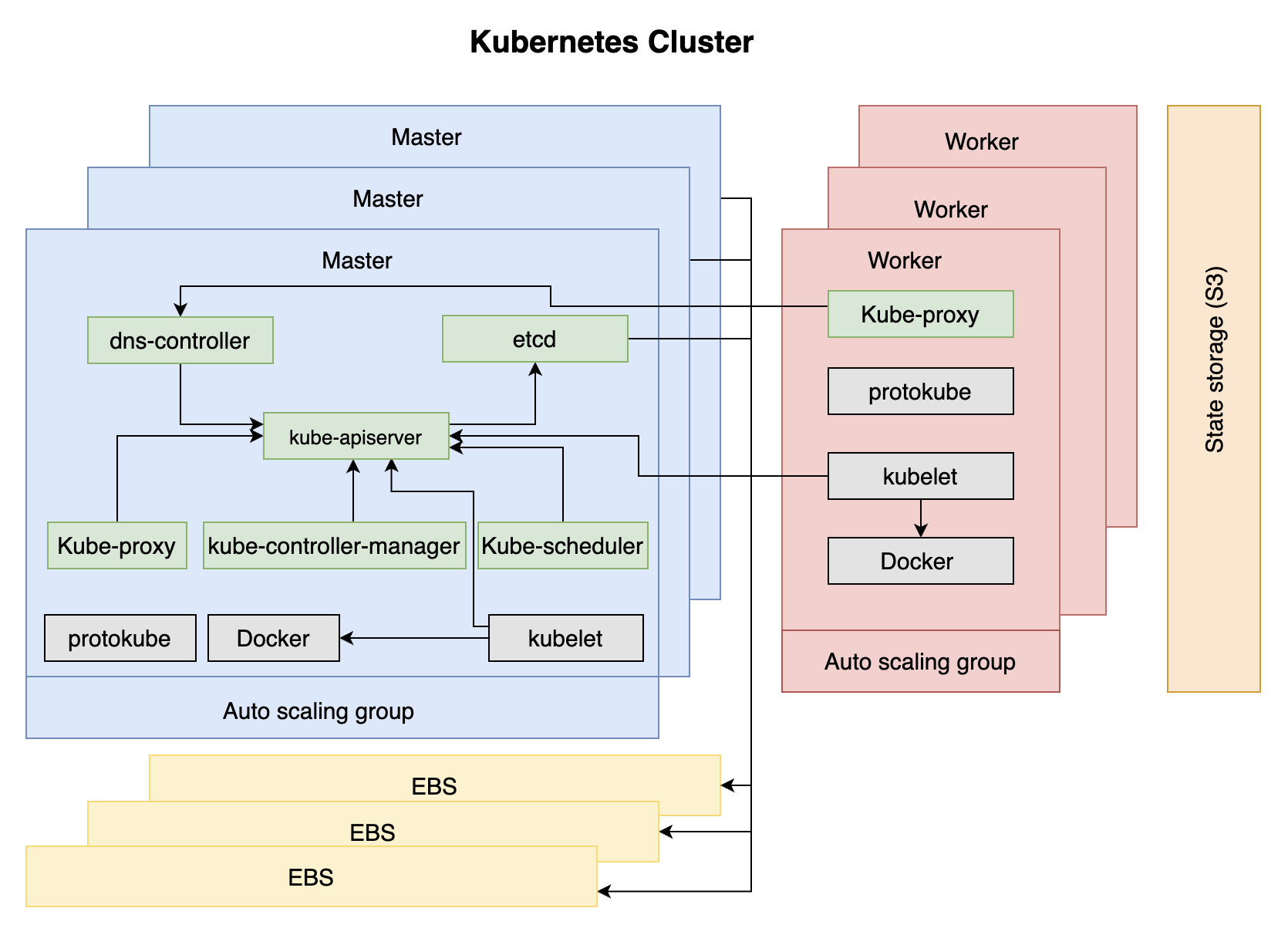
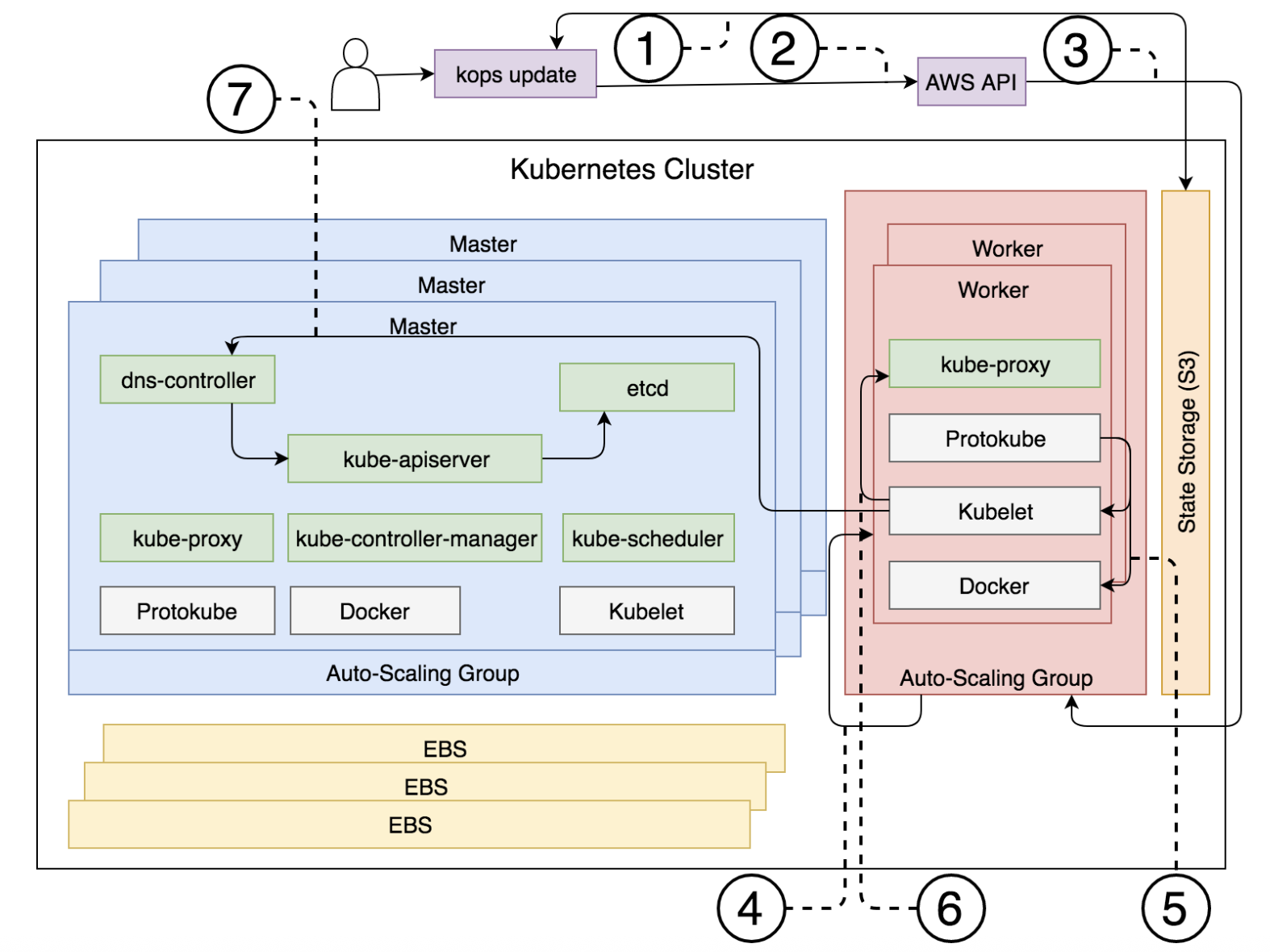
定义-构成集群的组件
当 kOps 创建 VM(EC2) 时,它做的第一件事时执行nodeup。安装一些软件包,确保 DOcekr, kubelet 和 protokube 启动并运行。
- Docker: 运行容器。
- Kubelet:
- Kubelete 是 Kubernetes 的节点代理,主要目的是运行 Pod,确保 PodSpecs 中描述的容器运行状况良好。它与 Kubertes API server 获取 pod 相关信息。
- 除了启动通过 manifest 中的 Pod 定义的容器(由 Protokube 创建)之外,Kubelet 还会尝试联系 API 服务器,然后 API 服务器最终启动。建立连接后,Kubelet 会注册运行它的节点。
- Protokube:
- 与 Docker 和 Kubelet 不同,Protokube 特定于 kOps。它的主要职责是发现和挂载主磁盘以及创建清单。Kubelet 使用其中一些清单来创建系统级 Pod 并确保它们始终运行。
所有三个软件包都在所有节点上运行,无论它们是主节点还是工作线程。
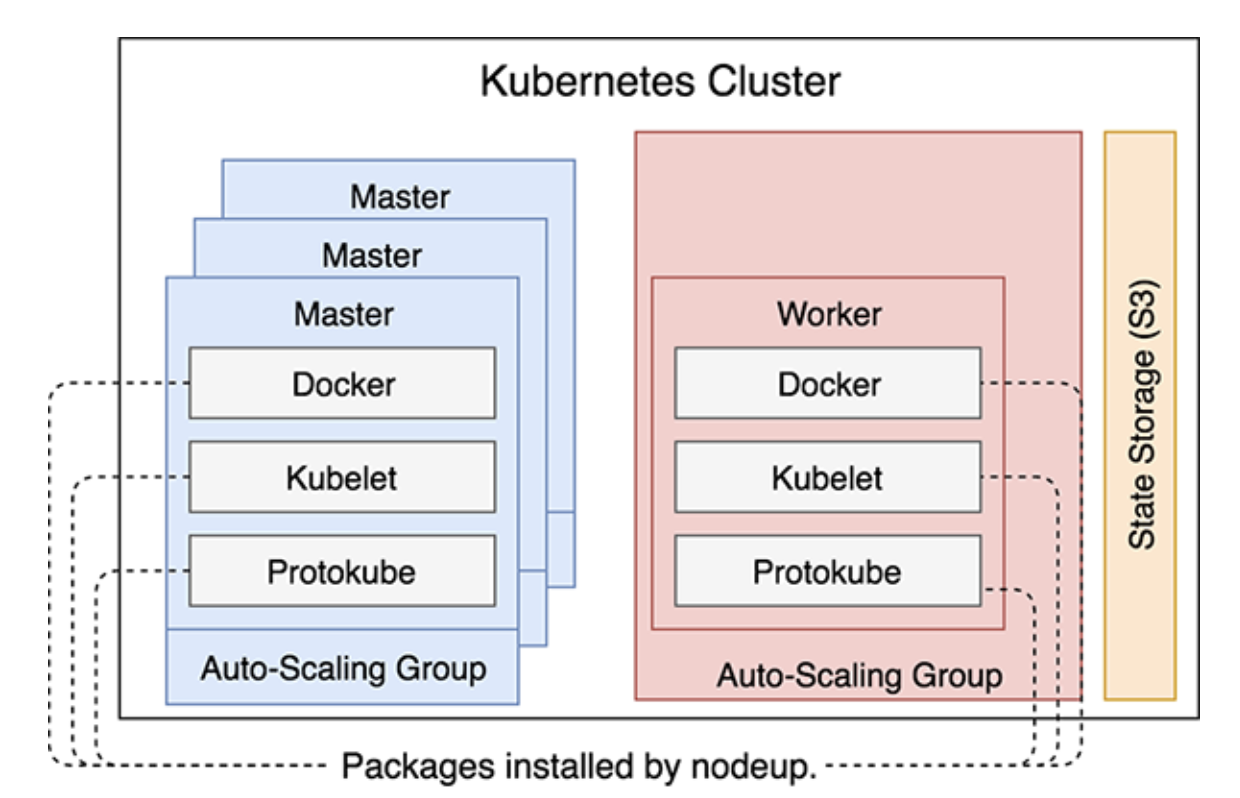
## 定义-构成集群的组件: 系统级组件
kubectl --namespace kube-system get pods
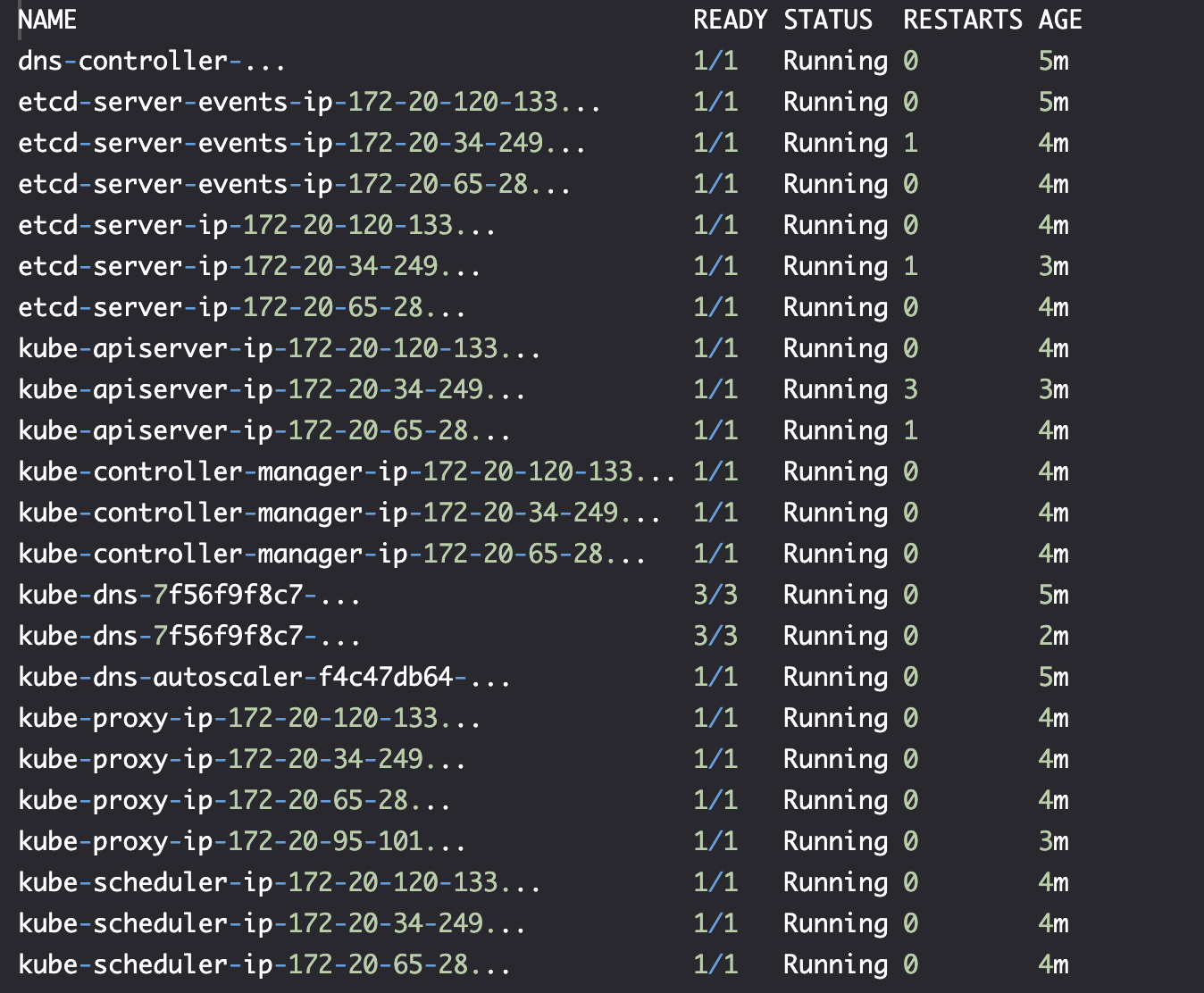
Primary components 主要组件
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- etcd
- dns-controller
Kubernetes API server
- 接受创建、更新或删除 Kubernetes 资源的请求。
- 80 服务于内部,443 服务于外部。
- 与 API server 的通信,目的都是验证和配置 API 对象,包括 Pods、Services、ReplicaSets 等。
- 它与用户交互,也与集群中所有组件交互,以分享集群共享状态。
- 集群共享状态存在 etcd 中,它是键值对存储,其中集群数据通过一致性的数据复制得以保持高可用。kOps 为每个 etcd 实例创建一个 EBS 卷。etcd 有两种 Pod:
- etcd-server 存储集群状态
- etcd-server-events 存储事件
Kubernetes controller manager
- 负责运行对象控制器,例如 ReplicaSet 和 Deployments 等。
- 除此之外,kube-controller-manager 还负责节点控制器,负责监控服务器并在服务器不可用时做出响应。
Kubernetes scheduler
Kubernetes 调度器会监视 API 服务器中的新 Pod 并将其分配给节点。从那时起,这些 Pod 由 Kubelet 在分配的节点上运行。
DNS controller
DNS 控制器允许节点和用户发现 API 服务器。
Node components 节点组件
- Kubernetes proxy
Kubernetes proxy
Kubernetes 代理反映了通过 API 服务器定义的服务。它负责 TCP 和 UDP 转发。它在集群的所有节点(主节点和工作线程)上运行。
实践-更新集群
kOps 无法直接更新集群,但是我们可以同归修改集群状态实现更新集群的目的。在我们的例子中,它存储在 S3bucket 里面。
kops edit --help

Edit cluster 修改集群
Cluster 无法修改节点数量。而且我们也不应该再 AWS 中创建服务器。
Edit instance group 修改实例组
通过修改 instance group 的 ASG 值,而不是发送创建指令创建新节点。更改后,AWS 将确保集群中的节点符合 ASG 的值,它不仅会确保数量,还会监控 EC2 实例,当其中有故障时也能够保证数量。
kops edit ig --name $CLUSTER_NAME nodes
之后会进入与 worker 节点关联的 InstanceGroup 配置,修改后保存:
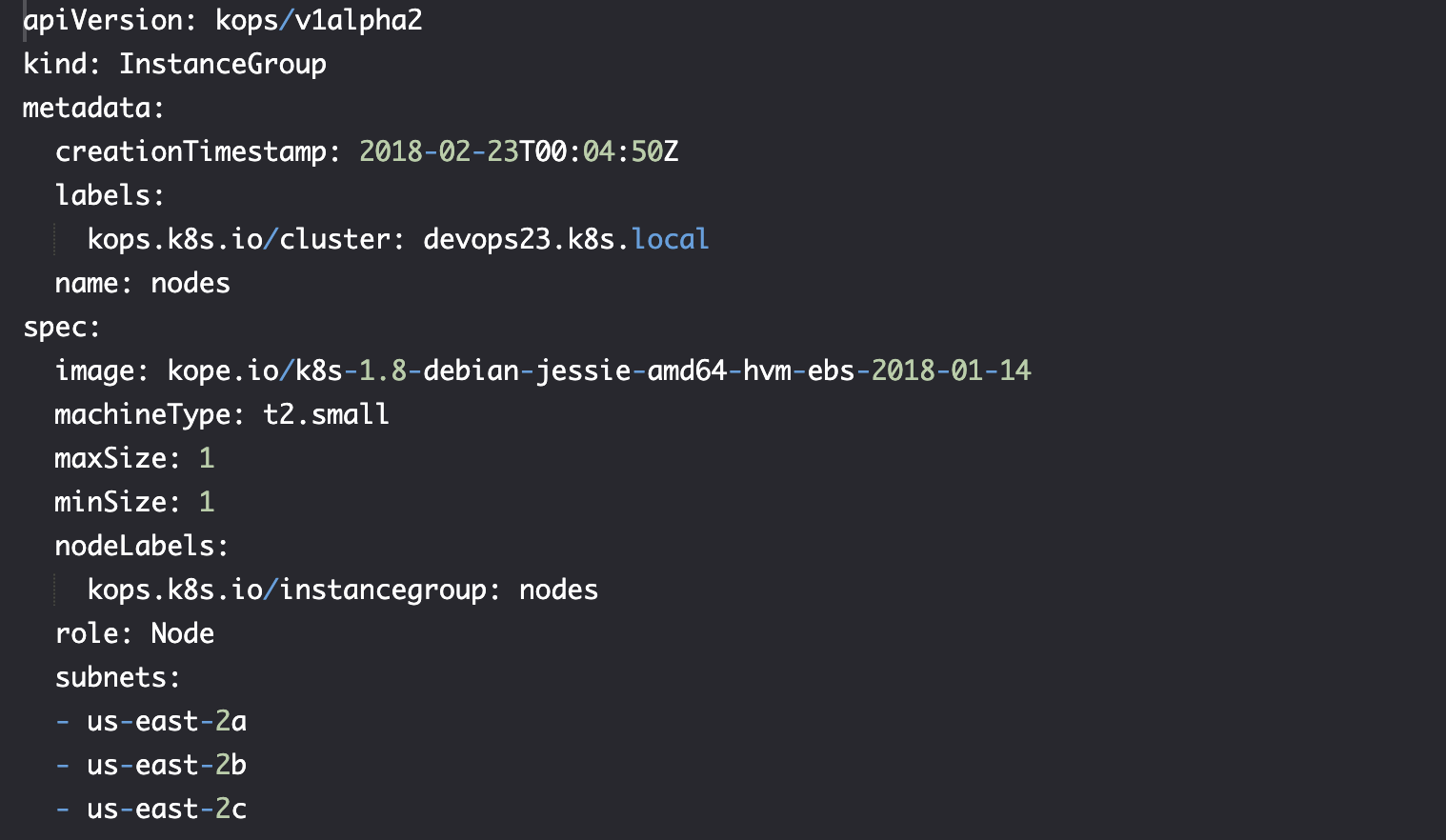
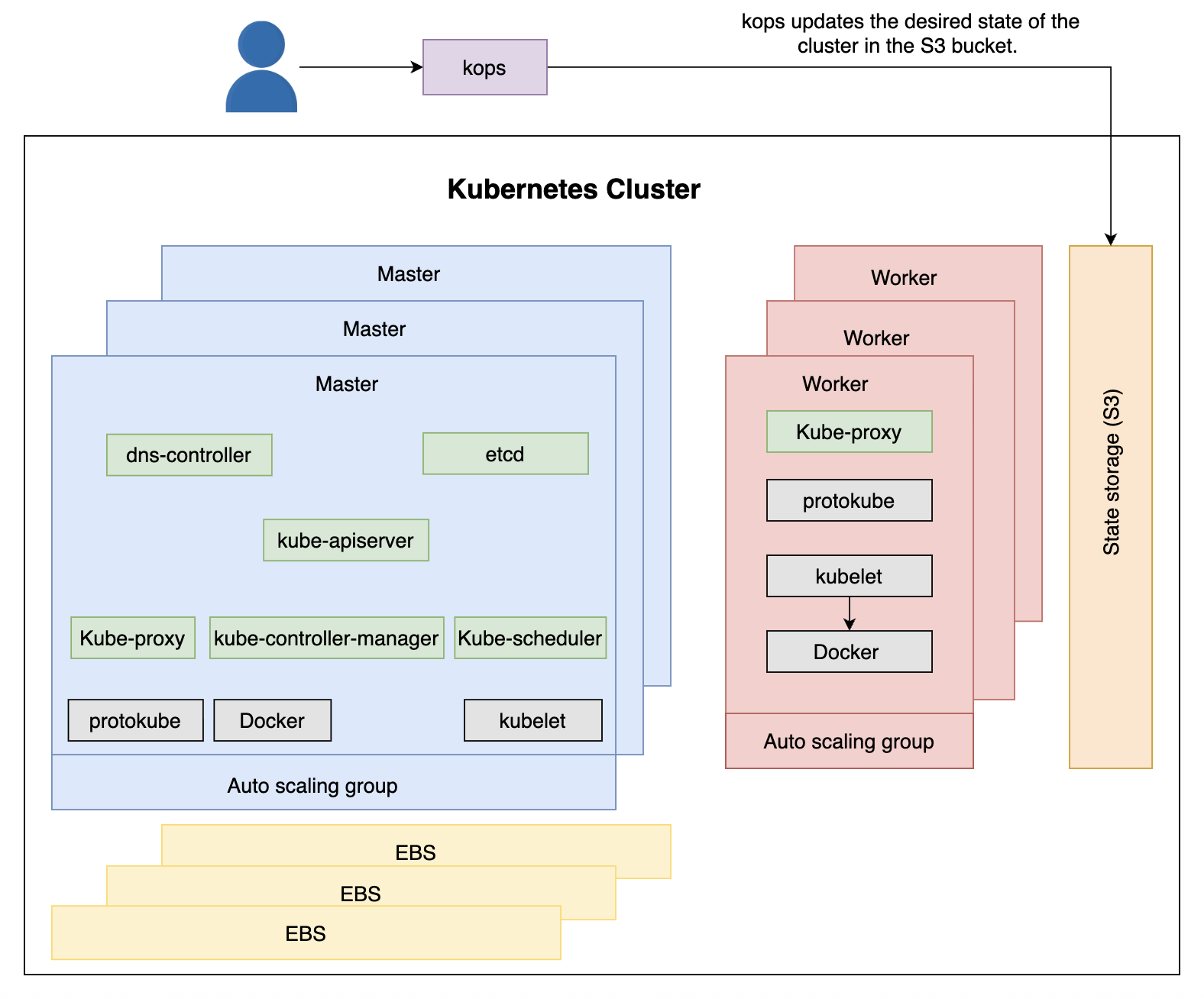
保存后,配置已修改,我们要告诉 kOps 希望它更新集群以符合最新状态:
kops update cluster --name $NAME --yes

- kOps 将我们的 kubectl 上下文修改为
devops23.k8s.local。 - 应用修改,同时我们会看到
kops rolling-update cluster, 如果用这个指令,一次只会更新一台服务器上的服务。如果应用程序是 scaled,使用它就不会产生停机。
更新过程中的顺序细分
- kOps 从 S3 存储桶中检索状态。
- kOps 向 AWS API 发送请求更改 workers ASG 的值。
- AWS 修改 workers ASG 的值 (+1)。
- ASG 创建一个新的 EC2 实例以符合新的 ASG 值。
- Protokube 安装 kubelet 和 Docker 组件,并创建 Pod 清单文件。
- Kubelet 读取清单文件并运行
kube-proxyPod (工作节点上唯一的 Pod) 容器。 - Kubelet 向
kube-apiserver发送请求 (通过dns-controller) 注册新节点并将其加入集群,新节点有关信息存储在etcd中。
verify
kops validate cluster
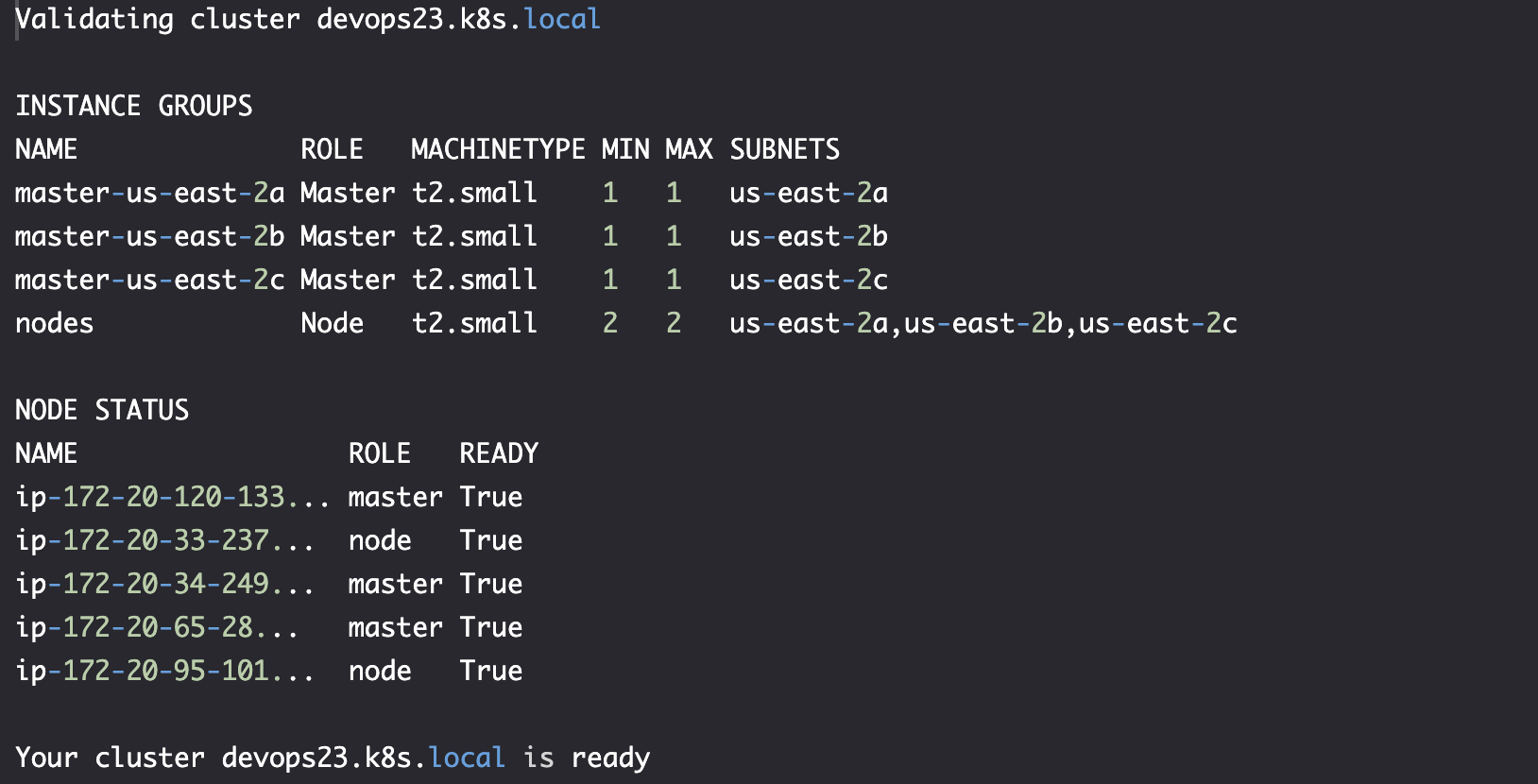
kubectl get nodes

实践-手动升级集群
kops edit cluster $NAME
修改集群 version from v1.9.1 to v1.9.2。
预览更新
kops update cluster $NAME
需要输入 yes以确定 update (鉴于此修改影响很大,先做个预览)。
仔细查看输出,了解哪些配置会改变。
应用更新 (x, 比较危险)
kops update cluster #NAME --yes
我们还是会看到 changes may require instances to restart: kops rolling-update cluster。
我们在此次更新不能够一次更新所有内容,这会产生停机时间。在我们的例子中,情况会更糟。
一次销毁所有节点可能导致 quorum 丢失,新集群无法恢复。
滚动更新
kops rolling-update cluster $NAME
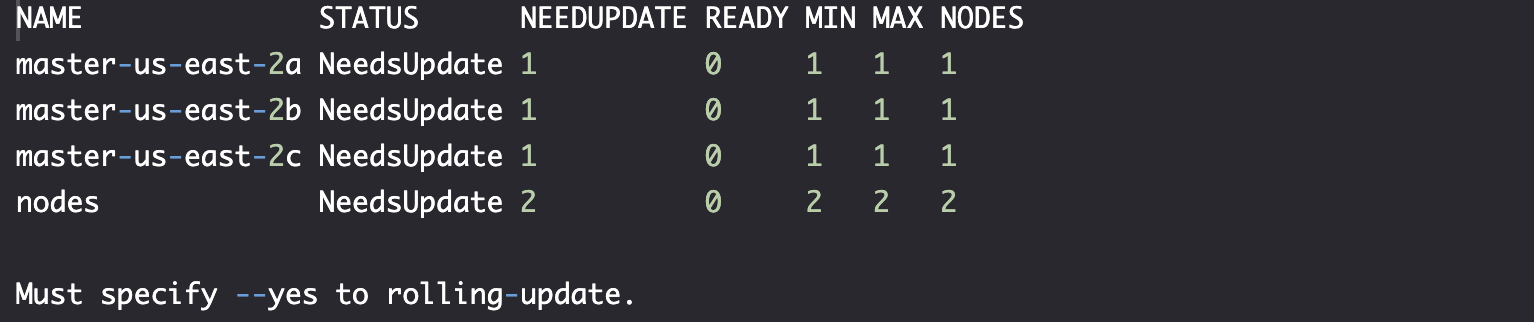
确定更新没问题后。
kops rolling-update cluster $NAME --yes
滚动更新启动,大约需要 30 分钟才能完成。
verify upgrade

kOps 不会销毁第一个节点,而是选择主节点并将其慢慢关掉(drain)。这样运行在上面的程序可以正常关闭:
etcd-server-eventsetcd-server-ipkube-apiserverkube-controller-managerkube-proxykube-scheduler- Pods running on the server
ip-172-20-40-167
Kubernetes 将 Pod 重新调度到另一个运行良好的节点。
![]()
在 draining 完成后,主节点停止了。由于每个主节点都与一个 ASG 关联,因此 AWS 将检测到该节点不再存在并启动一个新节点。
初始化新服务器后,nodeup 将执行并安装 Docker、Kubelet 和 Protokube。后者将创建 Kubelet 用于运行主节点所需的 Pod 的清单(首个 Pod 是 kube-proxy)。Kubelet 还会向其中一个运行状况良好的主节点注册新节点。

等待一切解决后,kOps 会验证集群,从而确认第一个主节点已成功升级。
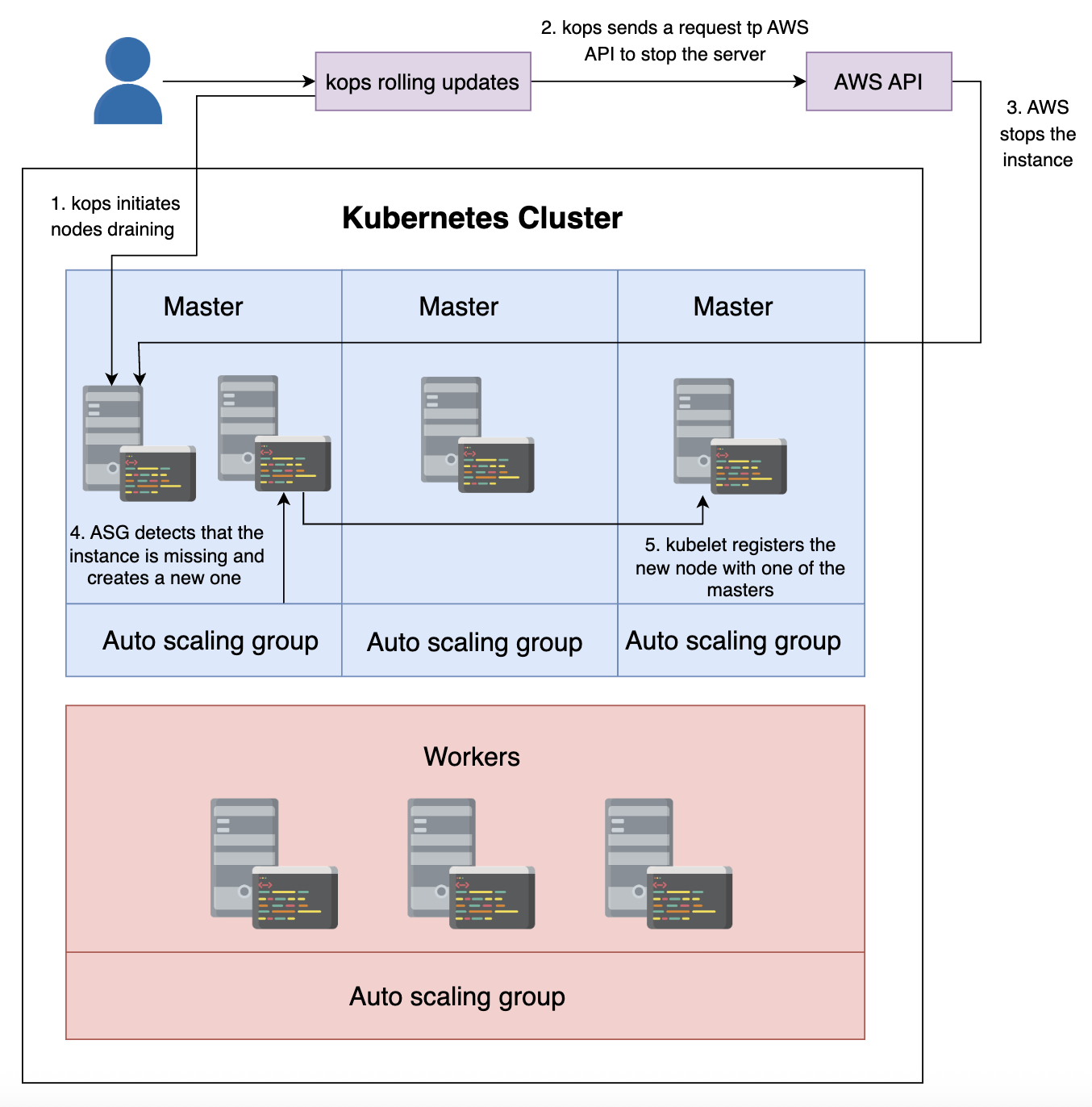
一旦验证了第一个主节点的升级,kOps 就会继续处理下一个节点。在接下来的 10 到 15 分钟内,将对其他两个主节点重复相同的过程。
升级所有三个节点后,kOps 将对 worker 节点执行相同的进程,我们将不得不再等待 10 到 15 分钟。
![]()
最后,所有服务器都升级了,我们可以看到滚动更新已完成。
verify
kubectl get nodes
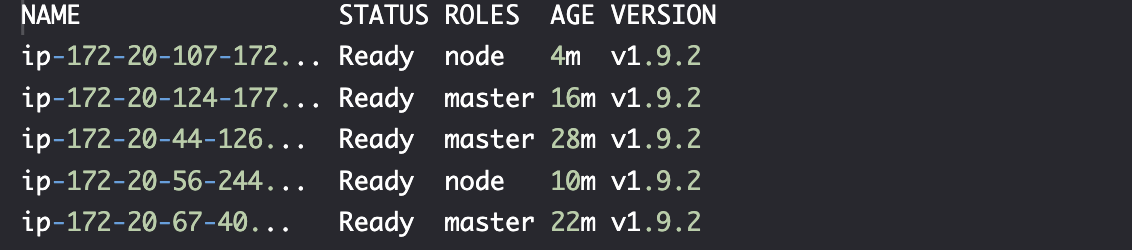
所有节点已经升级为 v1.9.2。
升级时要避免一次升级一个大版本,小步快跑式升级能够最大限度减少潜在问题,并在需要时简化回滚。
升级前需要验证: 即使 kOps 相当可靠,您也不应该盲目地相信它。创建一个运行与生产版本相同的小型测试集群,执行升级过程,并验证一切是否按预期工作,这相对容易。完成后,您可以销毁测试集群并避免不必要的费用。
注意: 不要相信任何人。在一个独立集群中先测试升级。
实践-自动升级集群
kops upgrade cluster $NAME --yes

kops update cluster $NAME --yes # changes may require instances to restart: kops rolling-update cluster
kops rolling-update cluster $NAME --yes
与手动升级相比,唯一显著区别是我们没有指定所需的版本,而是通过 kops upgrade 命令启动进程。
我们可以通过 CI/CD 创建一个每月升级的 CronJob: 如果没有新版本,则不执行工作;如果有,则创建一个与 production 版本相同的新集群,升级它,验证一切是否按预期工作,销魂 testing 集群,升级 production 集群,然后运行另一轮测试。
达到这一点需要时间和经验,在此之前,手动升级是可行的方法。
定义-了解访问集群协议
AWS ELB
到目前为止,我们使用 kubectl 通过 Kubernetes API 进行交互。这个 API 通信是通过 AWS Elastic Load Balancer (ELB) 建立。
aws elb describe-load-balancers
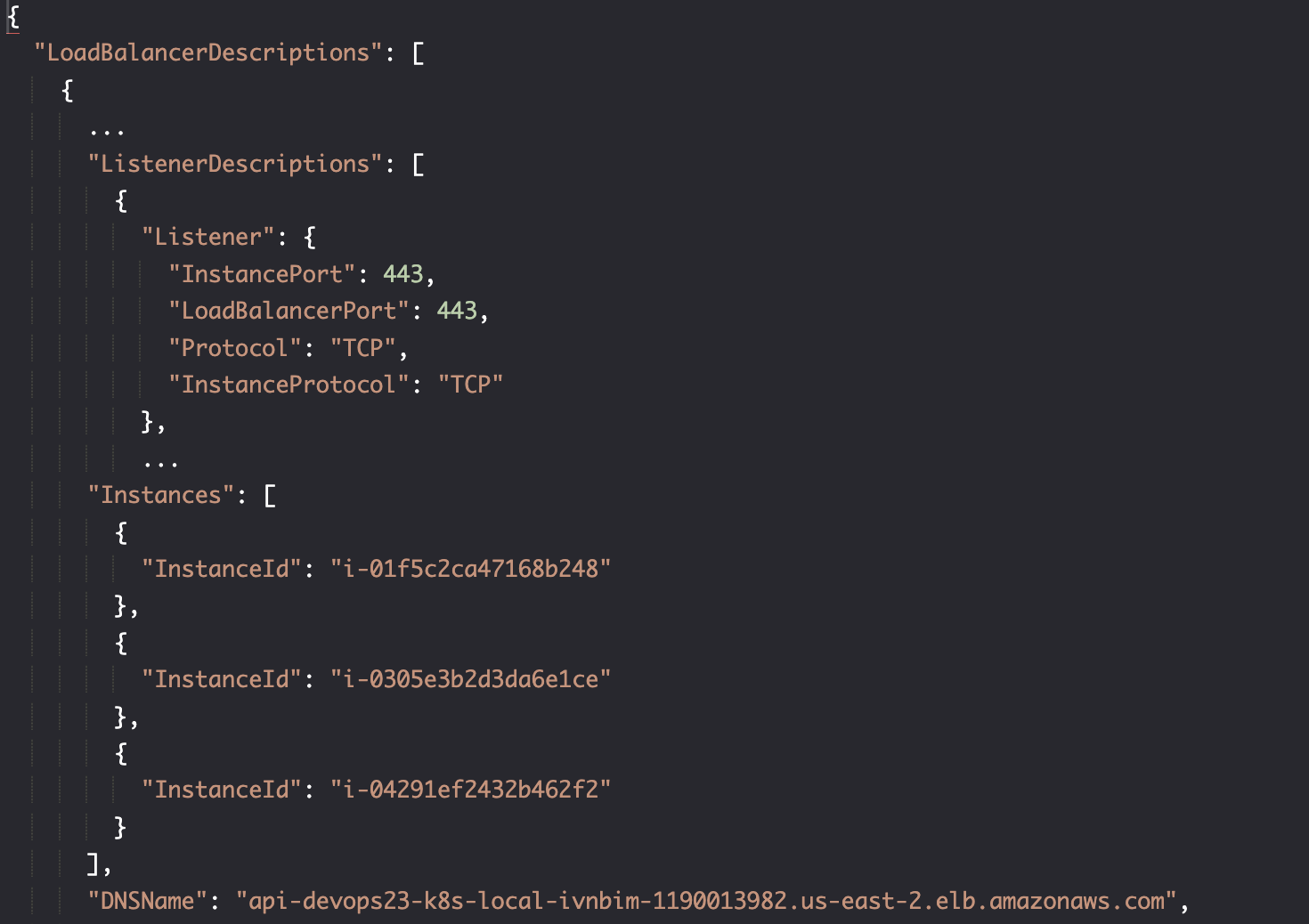
通过 ELB,我们可以与 master 节点交互。但仍缺少 worker 节点的访问权限。
负载均衡器的名称是: api-devops23-k8s-local-ivnbim。
kubectl 配置
kubectl config view
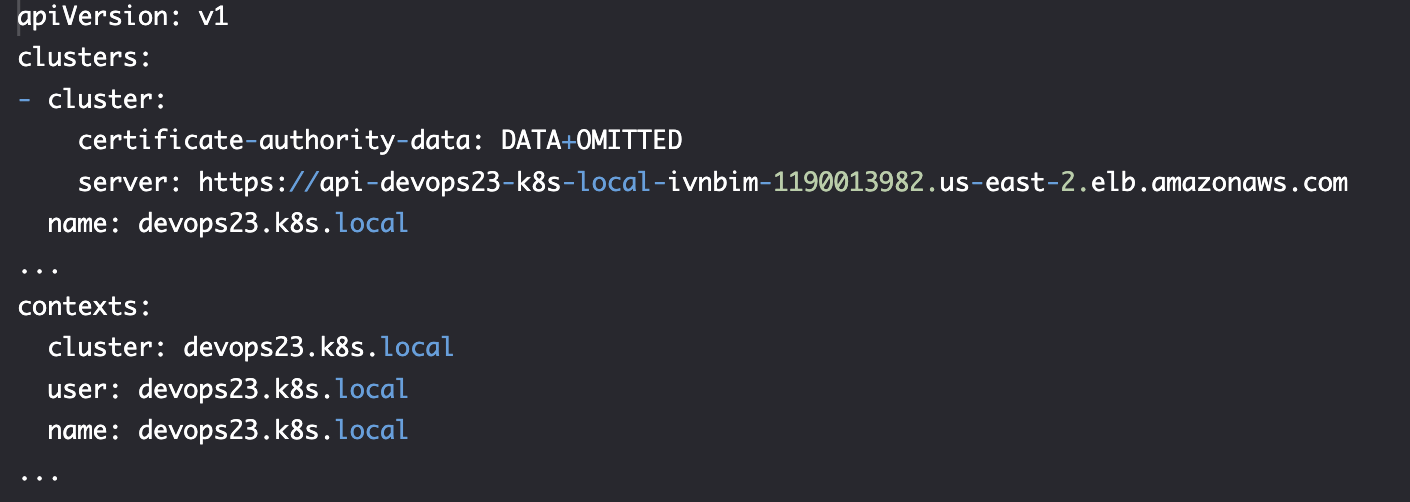
我们看到 devops23.k8s.local 被设置位使用 amazon.com 子域作为服务器地址,且它是当前上下文 context。
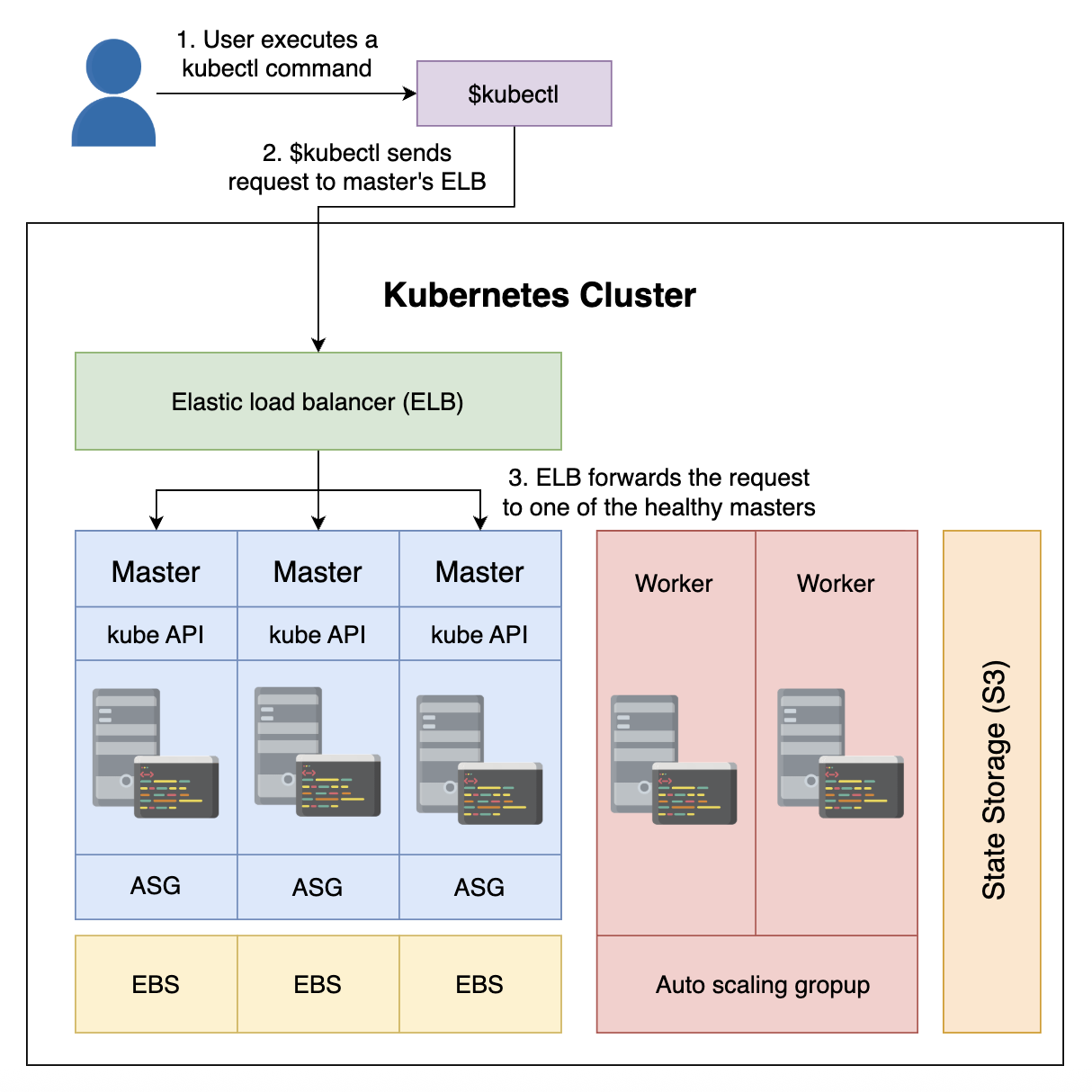
如果需要有办法访问 worker 节点,我们可以考虑使用 Ingress 生成将请求引导到一组端口(80 或 443)。
而 kOps 有另一个解决方法。
实践-访问集群: 添加负载均衡器
创建资源
kubectl create \
-f https://raw.githubusercontent.com/kubernetes/kops/master/addons/ingress-nginx/v1.6.0.yaml
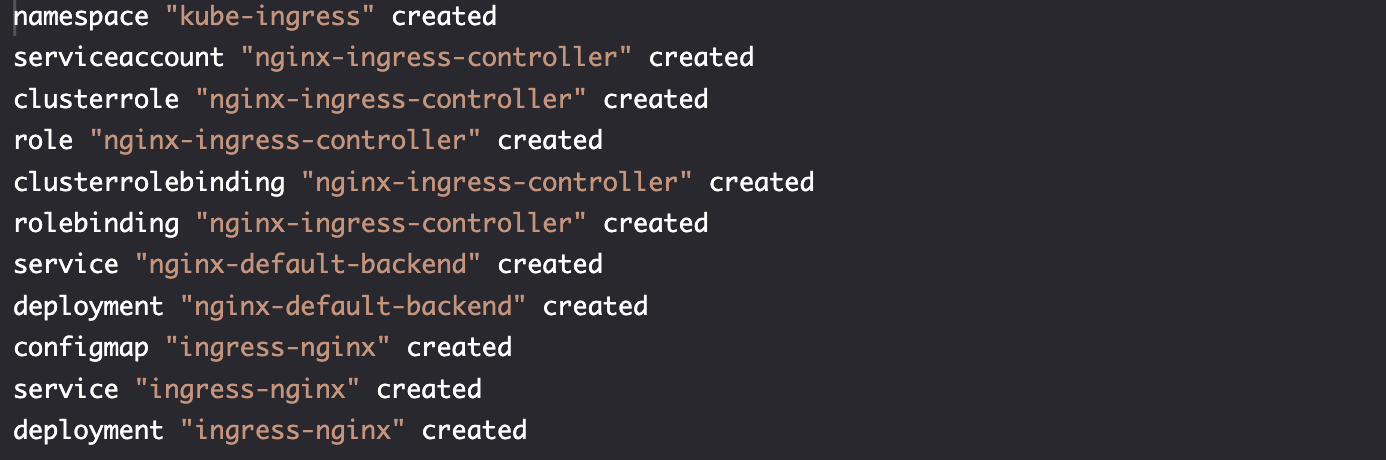
kubectl --namespace kube-ingress \
get all
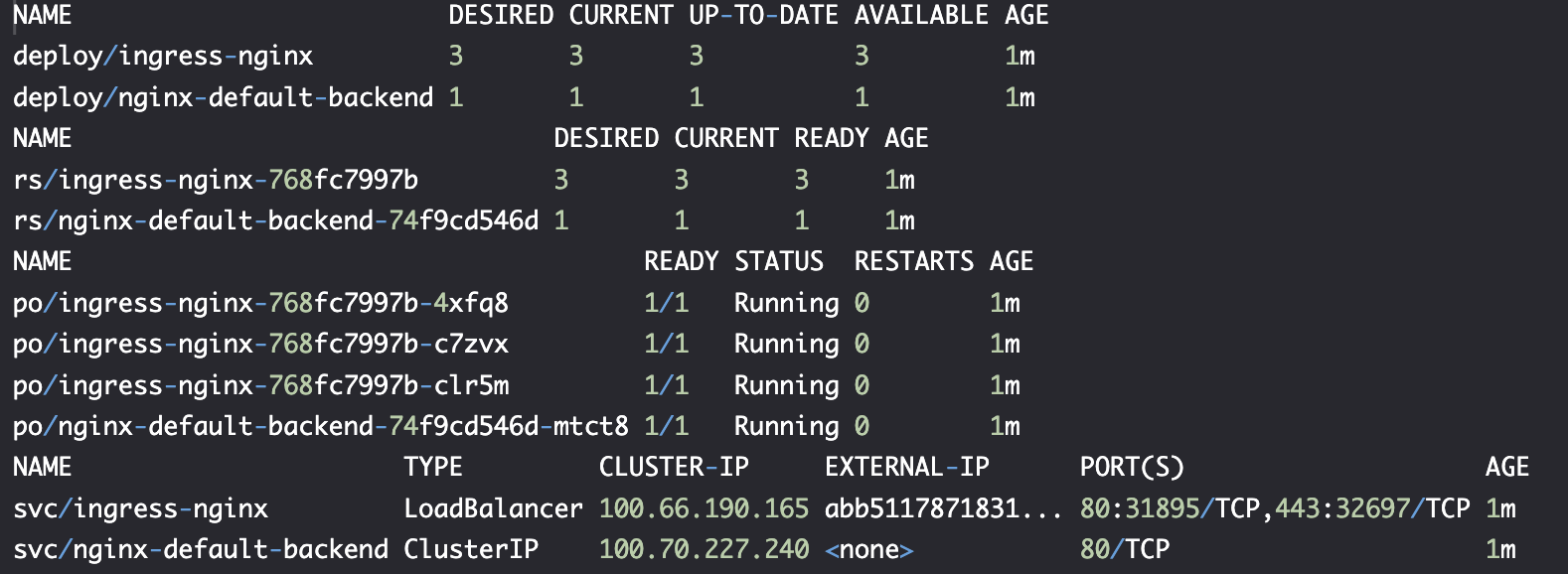
负载均衡器 Load balancer
svc/ingress-nginx 是负载均衡器,它将发布端口 31895 映射到 80,32697 映射到 443,服务类行为 LoadBalancer,这将对 ELB 配置产生影响。
verify
aws elb describe-load-balancers
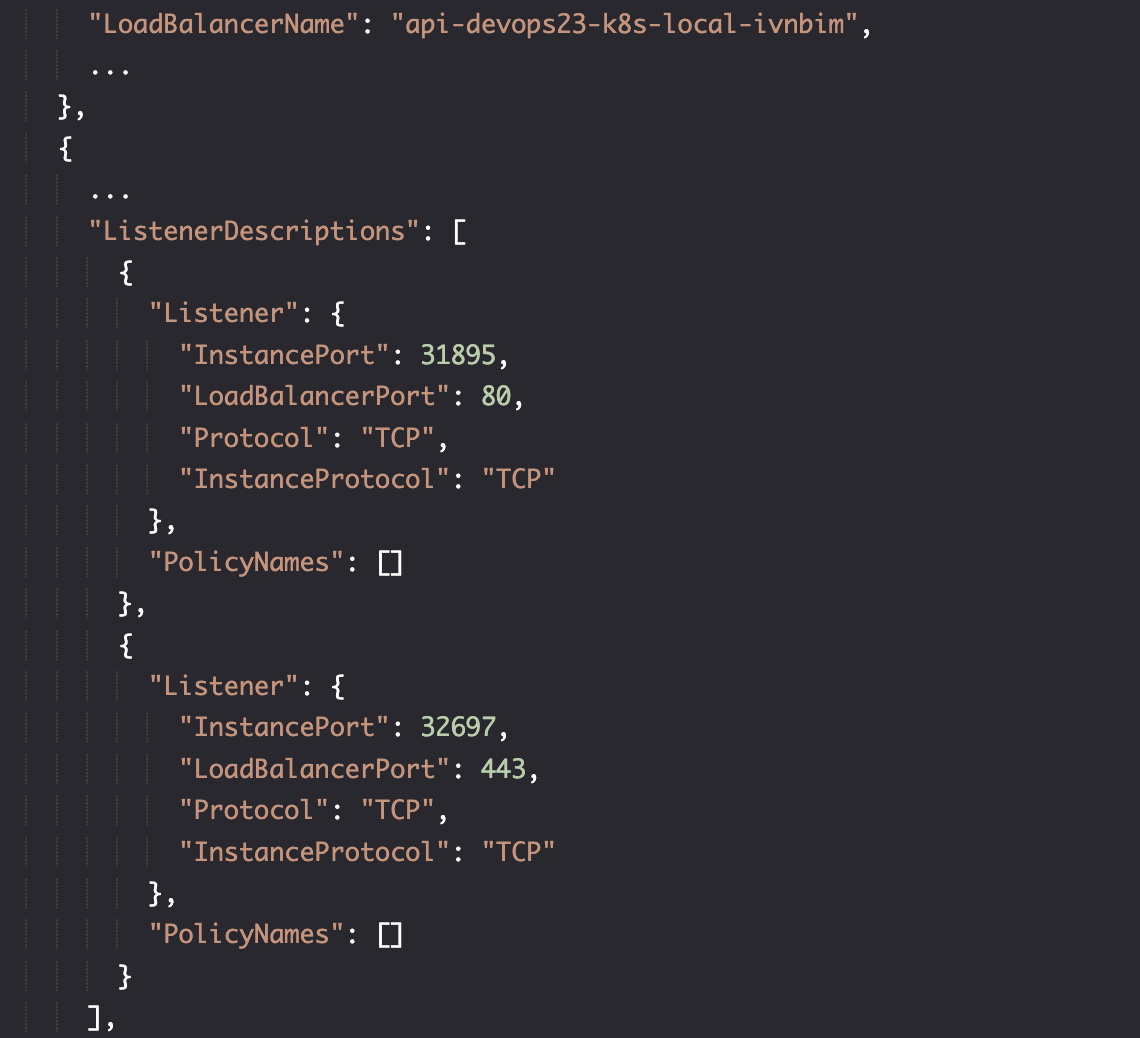
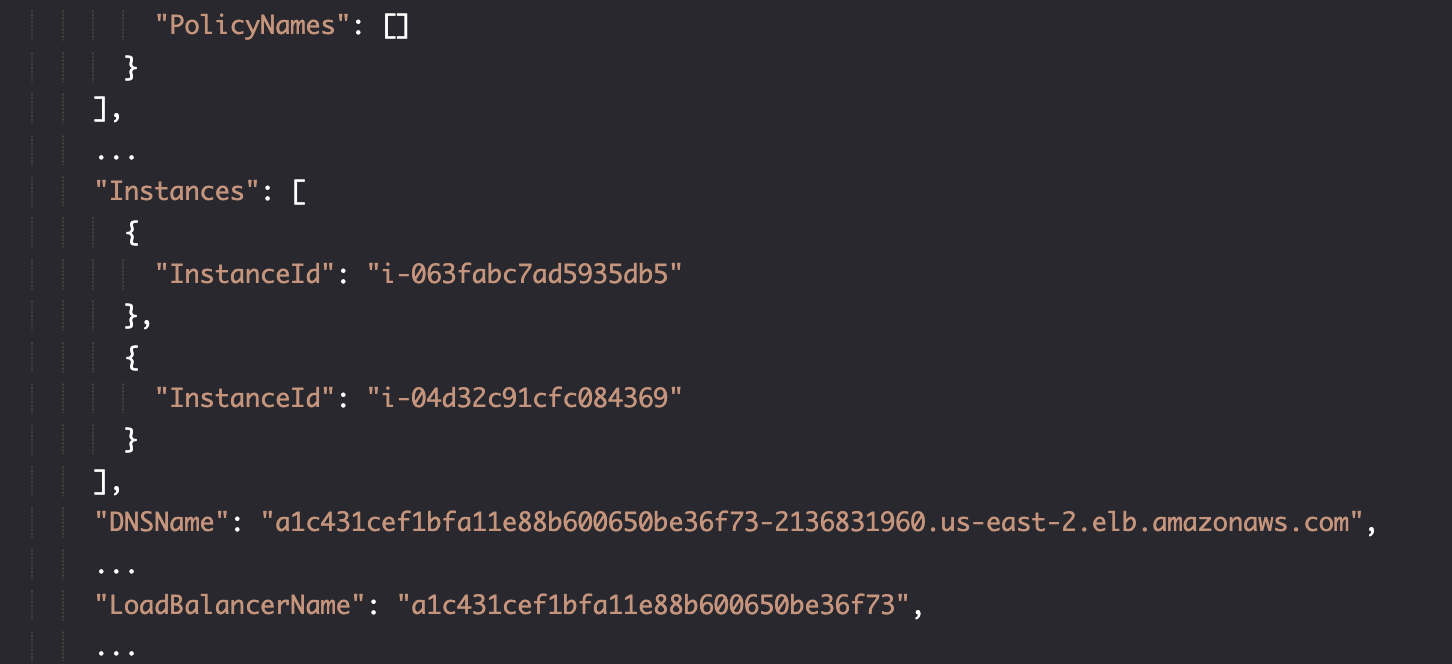
新的负载均衡器发布端口 80 映射到 31895,443 映射到 32697。在实例部分,它映射到两个 worker 节点。DNSName 不再是 api-devops23 开头,而是另一个。
我们能够确定的是,目前我们现在有两个 loadBalancer,其中一个服务于主节点,以 api-devops23开头,另一个指向工作节点。
使用 jq 指令寻找工作节点负载均衡器(排除 api-devops23),并存储 CLUSTER_DNS:
CLUSTER_DNS=$(aws elb \
describe-load-balancers | jq -r \
".LoadBalancerDescriptions[] \
| select(.DNSName \
| contains (\"api-devops23\") \
| not).DNSName")
部署资源
kOps 成为云服务提供商和 Kubernetes 集群中间的抽象层,这个层能够让我们轻松在不同的云服务商之间切换。
cd ~/k8s-specs
kubectl create \
-f aws/go-demo-2.yml \
--record --save-config

kubectl rollout status \
deployment go-demo-2-api
![]()
curl -i "http://$CLUSTER_DNS/demo/hello"
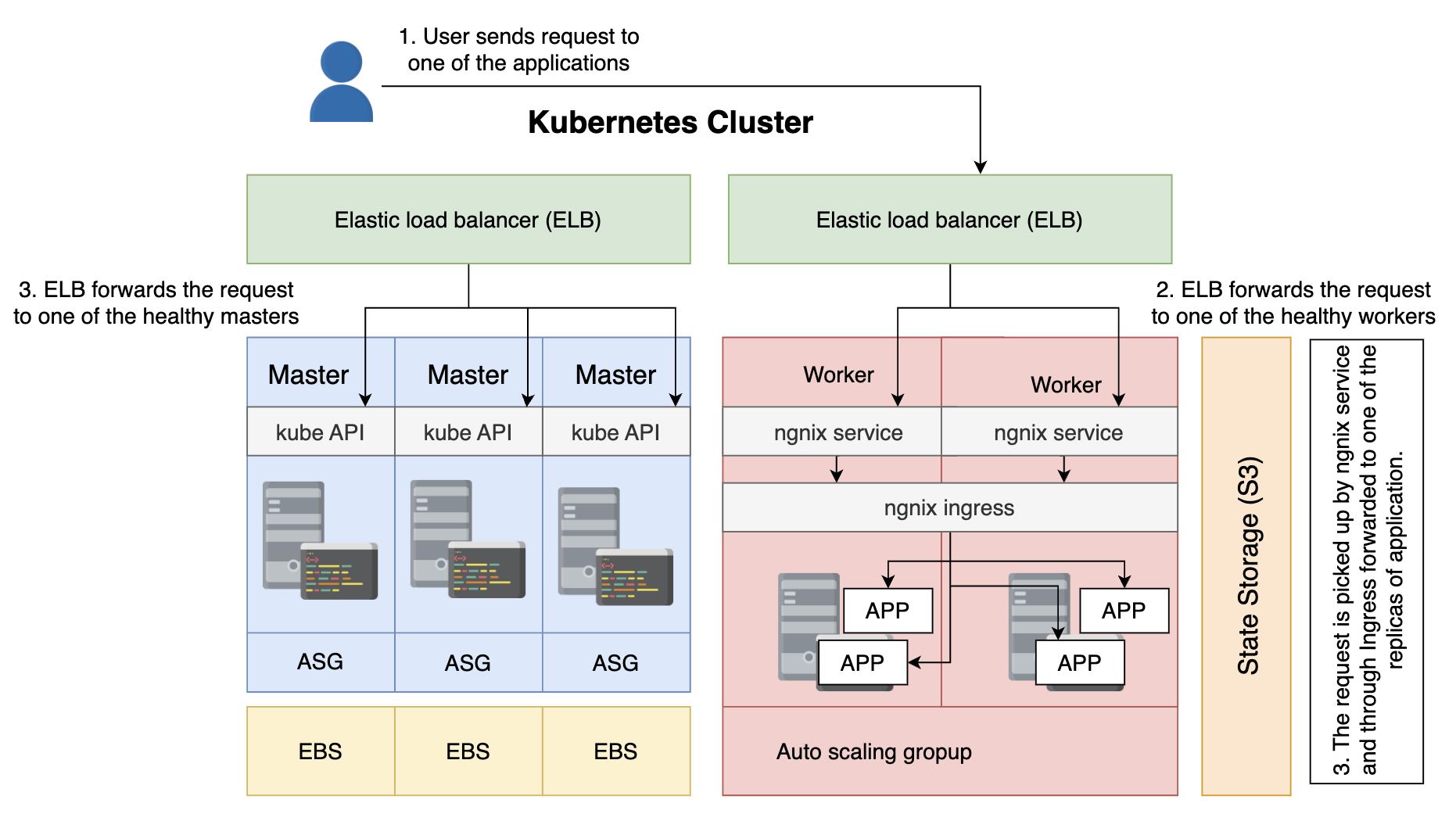
工作节点运行我们的程序,主节点则专用于运行 Kubernetes 系统。将两种节点分开,可以让整个系统更加可靠。
实践-集群高可用性和容错能力
终止工作节点
使用 describe-instances 检索所有实例,按照 Worker 节点安全组筛选:
aws ec2 \
describe-instances | jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.InstanceId"

随机中止一个节点
INSTANCE_ID=$(aws ec2 \
describe-instances | jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.InstanceId" | tail -n 1)
aws ec2 terminate-instances \
--instance-ids $INSTANCE_ID
实例正在关闭:
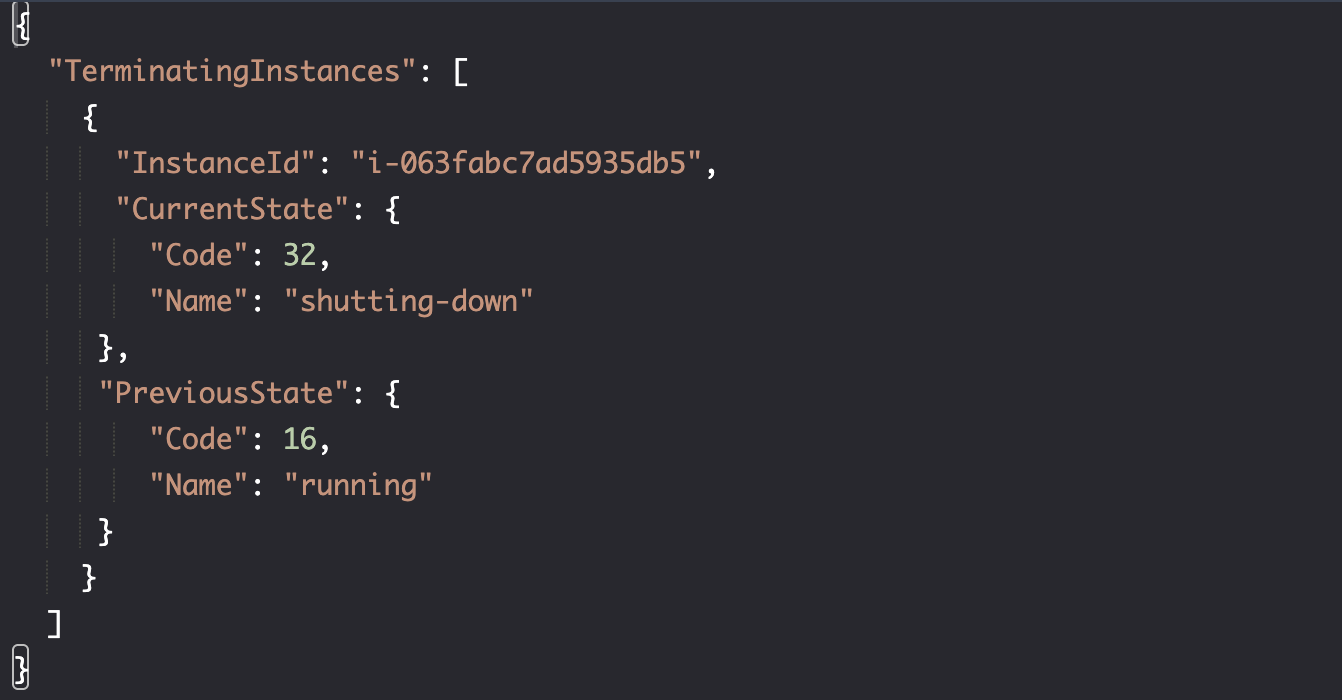
确认实例已关闭:
aws ec2 describe-instances | jq -r \
".Reservations[].Instances[] \
| select(\
.SecurityGroups[].GroupName \
==\"nodes.$NAME\").InstanceId"

kubectl get nodes

启动新服务器,安装 Docker, Kubelet 和 Protokube 需要时间,等待实例重启动后
aws ec2 \
describe-instances | jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.InstanceId"
其中一个实例与之前不同:

kubectl get nodes

上述情况与我们执行滚动升级时基本相同。唯一的区别是,我们终止实例是为了模拟故障。
我们也可以对主节点进行类似的测试,唯一的区别是需要使用 masters 而不是 nodes作为安全组的名称前缀。
实践-授予其他人对集群的访问权限
如果要给别人访问权限,需要创建 kubectl 配置。
创建 Distributable 配置
cd cluster
mkdir -p config
export KUBECONFIG=$PWD/config/kubecfg.yaml
kops export kubecfg --name ${NAME}
cat $KUBECONFIG
将 kops 配置输出到kubecfg.yaml文件。
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: ...
server: https://api-devops23-k8s-local-ivnbim-609446190.us-east-2.elb.amazonaws.com
name: devops23.k8s.local
contexts:
- context:
cluster: devops23.k8s.local
user: devops23.k8s.local
name: devops23.k8s.local
current-context: devops23.k8s.local
kind: Config
preferences: {}
users:
- name: devops23.k8s.local
user:
as-user-extra: {}
client-certificate-data: ...
client-key-data: ...
password: oeezRbhG4yz3oBUO5kf7DSWcOwvjKZ6l
username: admin
- name: devops23.k8s.local-basic-auth
user:
as-user-extra: {}
password: oeezRbhG4yz3oBUO5kf7DSWcOwvjKZ6l
username: admin
之后,将文件分享给同事,他就有跟你一样的权限访问集群。
更好的办法是创建新用户和密码;或者更好是创建 SSH 密匙,让组织中每个用户使用自己的身份访问集群;同时配置 RBAC 权限。
实践-销毁集群
保存所有需要的变量名,以便下次使用:
kops 文件:
echo "export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID
export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY
export AWS_DEFAULT_REGION=$AWS_DEFAULT_REGION
export ZONES=$ZONES
export NAME=$NAME
export KOPS_STATE_STORE=$KOPS_STATE_STORE" \
>kops
删除集群
kops delete cluster \
--name $NAME \
--yes
kops 删除kubectl配置中所有引用到的资源以及相关的 AWS 资源。

aws s3api delete-bucket \
--bucket $BUCKET_NAME
IAM 资源我们将保留,你也可以用其他工具(Terraform) 来保存配置。下列是手动删除的指令:
# Replace `[...]` with the administrative access key ID.
export AWS_ACCESS_KEY_ID=[...]
# Replace `[...]` with the administrative secret access key.
export AWS_SECRET_ACCESS_KEY=[...]
aws iam remove-user-from-group \
--user-name kops \
--group-name kops
aws iam delete-access-key \
--user-name kops \
--access-key-id $(\
cat kops-creds | jq -r \
'.AccessKey.AccessKeyId')
aws iam delete-user \
--user-name kops
aws iam detach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess \
--group-name kops
aws iam detach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess \
--group-name kops
aws iam detach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonVPCFullAccess \
--group-name kops
aws iam detach-group-policy \
--policy-arn arn:aws:iam::aws:policy/IAMFullAccess \
--group-name kops
aws iam delete-group \
--group-name kops