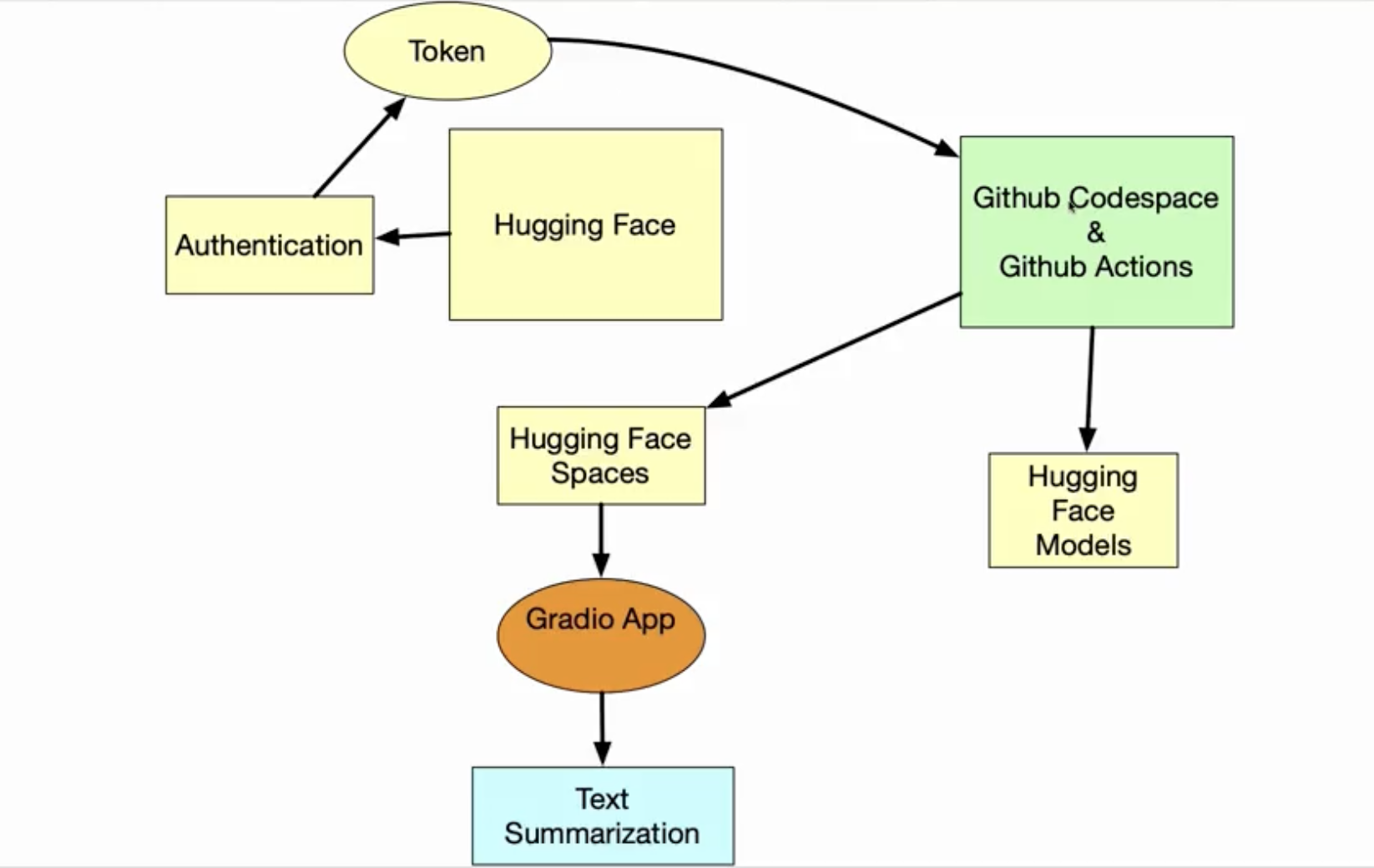
实践-端对端 MLOps Huggingface spacesJuly 22, 2025 · 2 min read框架 使用 Github CI 推送 模型 到 Huggingface Spacers。
数据科学July 22, 2025 · 3 min read Jupyter Notebook- 一种开源网络应用程序,用于创建和共享包含实时代码、可视化和文本的文档。 Colab Notebook- 由谷歌托管的 Jupyter 笔记本,可免费使用 GPU 和机器学习工具。 GitHub- Git 仓库托管服务,用于存储和管理代码以及跟踪更改。支持协作。 虚拟环境- 一种隔离的 Python 环境,允许安装用于特定应用程序的软件包,而不是全局安装。 README 文件- 介绍和解释项目的文本文件。它包含的信息有助于他人理解和贡献。 需求文件- 列出运行应用程序所需的所有 Python 软件包依赖关系的文本文件。允许重复构建。 Makefile- 包含一系列指令的文件,用于自动构建、测试和管理项目。 持续集成- 经常合并代码更改并自动构建和测试代码以快速发现问题的做法。 数据科学家的一天 数据推理分析框架 Data Science Structure Ingest EDA (Exploratory Data Analysis) Modeling: Learning Data -> Predict Conclusion: Strong Recommendation + Data support
MLOps 关键概念July 21, 2025 · 3 min read关键术语 MLOps 平台:专门的软件解决方案和工作流程,用于操作机器学习模型。MLOps 平台具有数据标记、模型监控、特征存储和优化模型服务等功能。 持续集成(CI):一种自动化软件开发实践,开发人员经常将代码变更合并到共享存储库中。然后自动构建和测试变更,以便及早发现问题。 持续交付:一种软件工程方法,团队在短周期内生产软件,确保软件可随时可靠发布。它依赖于自动化(如基础设施即代码)来复制测试/开发环境。 基础设施即代码:通过代码而不是人工流程来管理和配置基础设施。这样,环境配置、部署和管理就可以在各个开发阶段保持一致和可重复。 功能存储:集中式存储库,用于存储机器学习模型训练所需的特征。这有助于管理用于模型创建、存储和发现的数据,同时防止漂移。
什么是 MLOps?July 20, 2025 · 3 min readDevOps, DataOps 和 MLOps 术语 MLOps - DevOps 式自动化方法与 ML 最佳实践的结合,侧重于将 ML 模型部署到生产系统中并进行操作。 DevOps- 协作文化和开发人员自动化操作,以持续改进部署并减少业务部门之间的摩擦。包括 CI/CD 等自动化工具和原则。 CI/CD- 持续集成和持续交付 - DevOps 工作流程中的关键实践。CI 包括定期自动测试和验证增量构建的软件,而 CD 则侧重于自动向生产等环境发布更新。 成熟度模型 - MLOps 中的概念,定义了 MLOps 复杂性和有效性的递增级别,通常为 4-5 级,从手动、孤立、不可靠到可扩展、自主和弹性系统。 数据运维- 具体侧重于使用 DevOps 概念和自动化原则来管理数据工作负载,如聚合、转换、存储、分析等。 特征存储- 用于管理、存储和提供 ML 特征的中央存储库,以便构建模型和进行再培训。优化数据管道和重用。
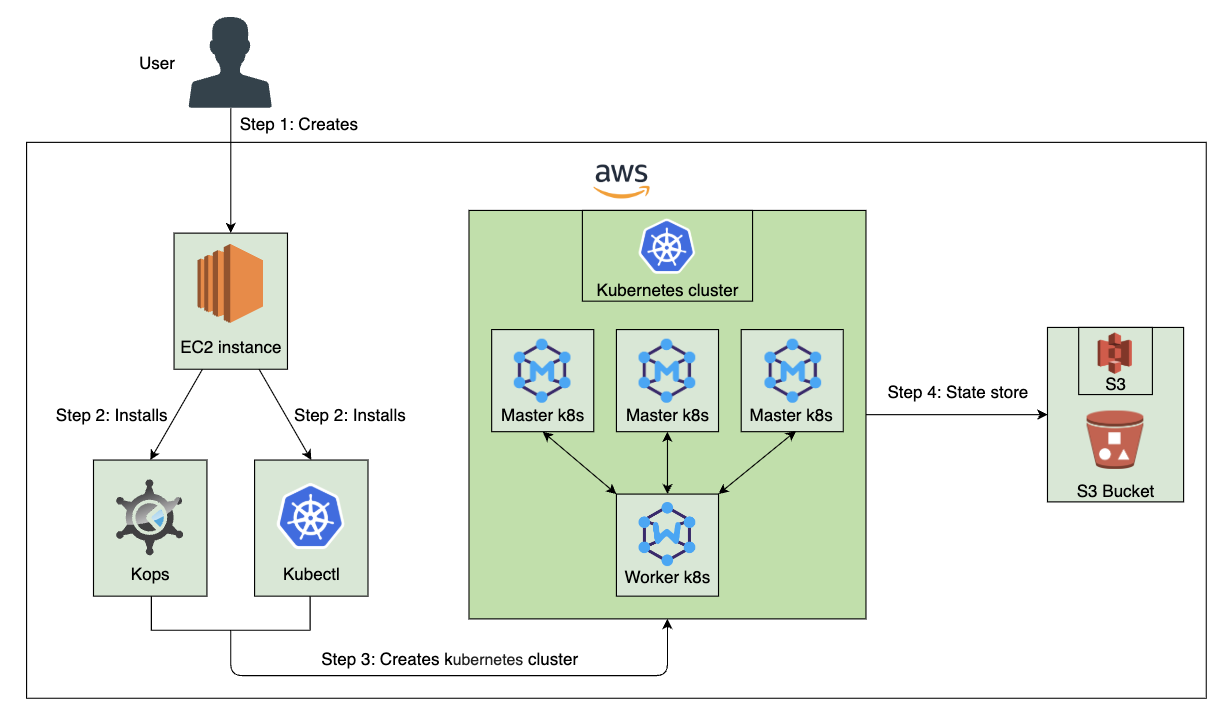
Kubernetes 理论与实践-5-搭建生产环境集群-kOps, AWSJuly 15, 2025 · 19 min read前文回顾 资源分配 服务质量合同 QoS (Quality of Service) 命名空间中的资源默认值和限制, 配额 ResourceQuota Kubernetes 理论与实践-4-资源管理
Kubernetes 理论与实践-4-资源管理-CPU, Memory, QoS, ResourceQuotaJuly 12, 2025 · 21 min read前文回顾 Kubernetes 理论与实践-3-安全与权限管理
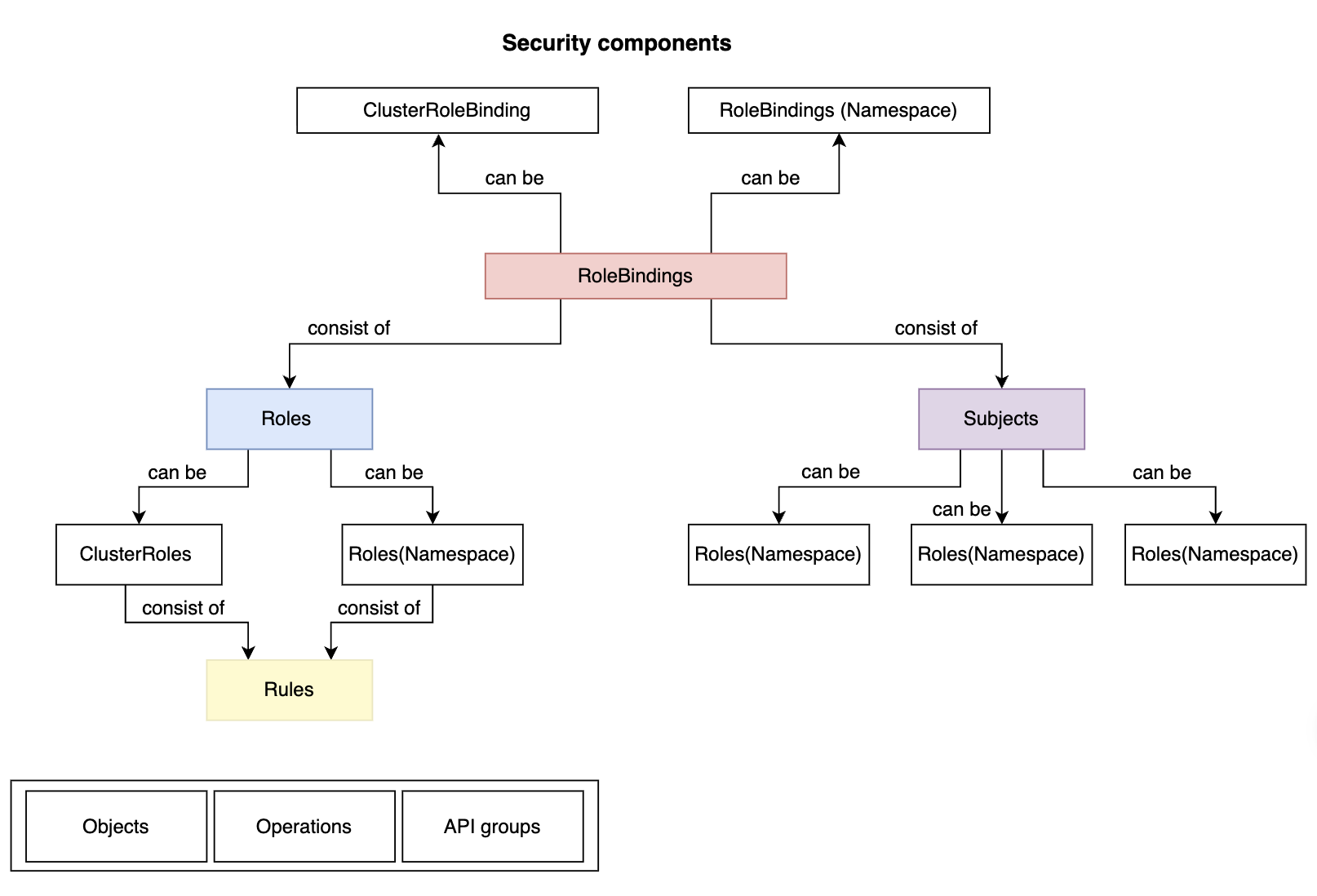
Kubernetes 理论与实践-3-安全与权限管理-RBAC, Rules, Roles, RoleBindings, SubjectsJuly 11, 2025 · 12 min read前文回顾 Kubernetes 理论与实践-2-存储-Volumes, ConfigMaps, Secrets, Namespaces
Kubernetes 理论与实践-2-存储-Volumes, ConfigMaps, Secrets, NamespacesJuly 10, 2025 · 18 min read前文回顾 Kubernetes 理论与实践-1-基础-Pods, ReplicaSets, Services, Deployments
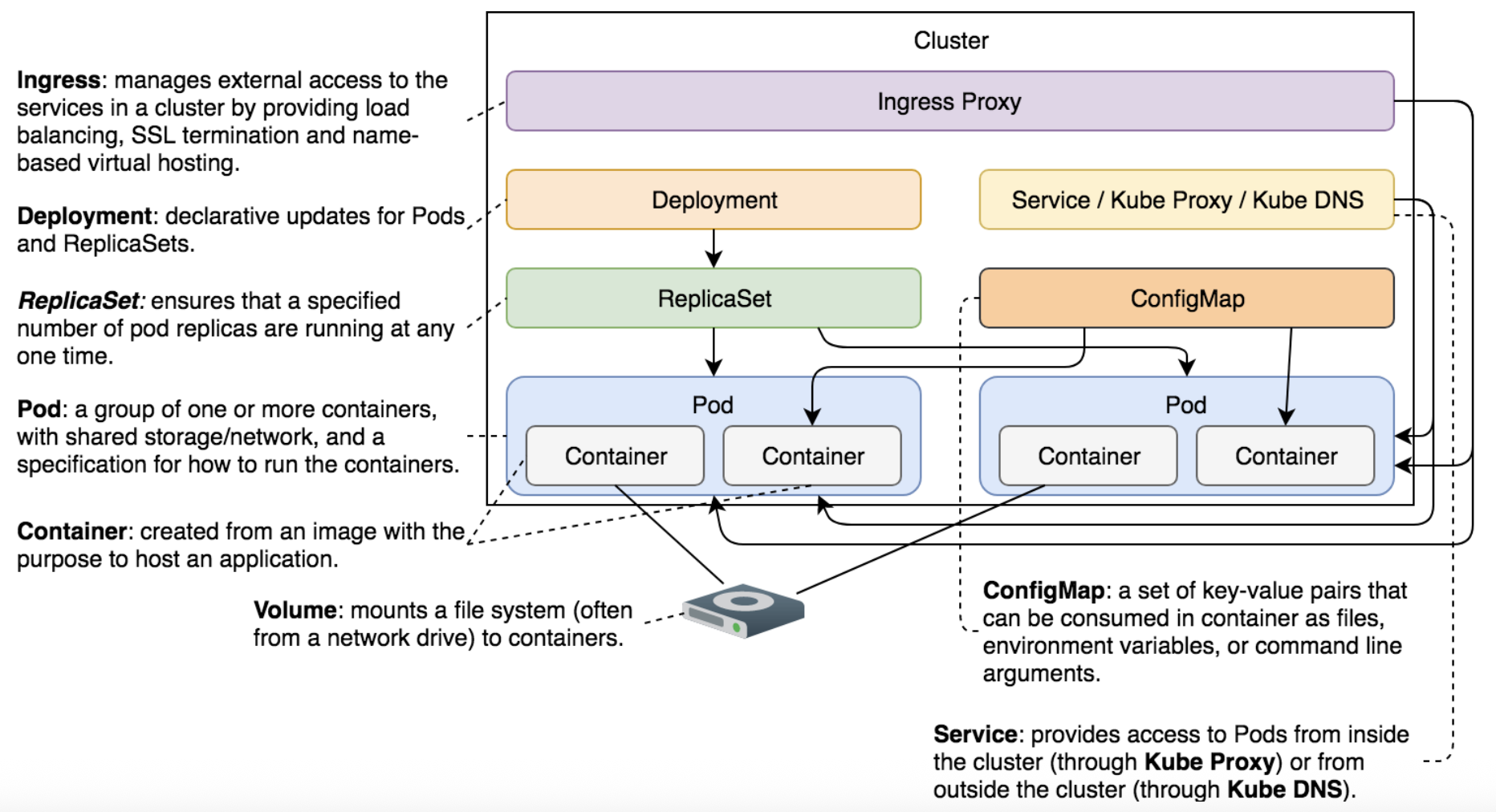
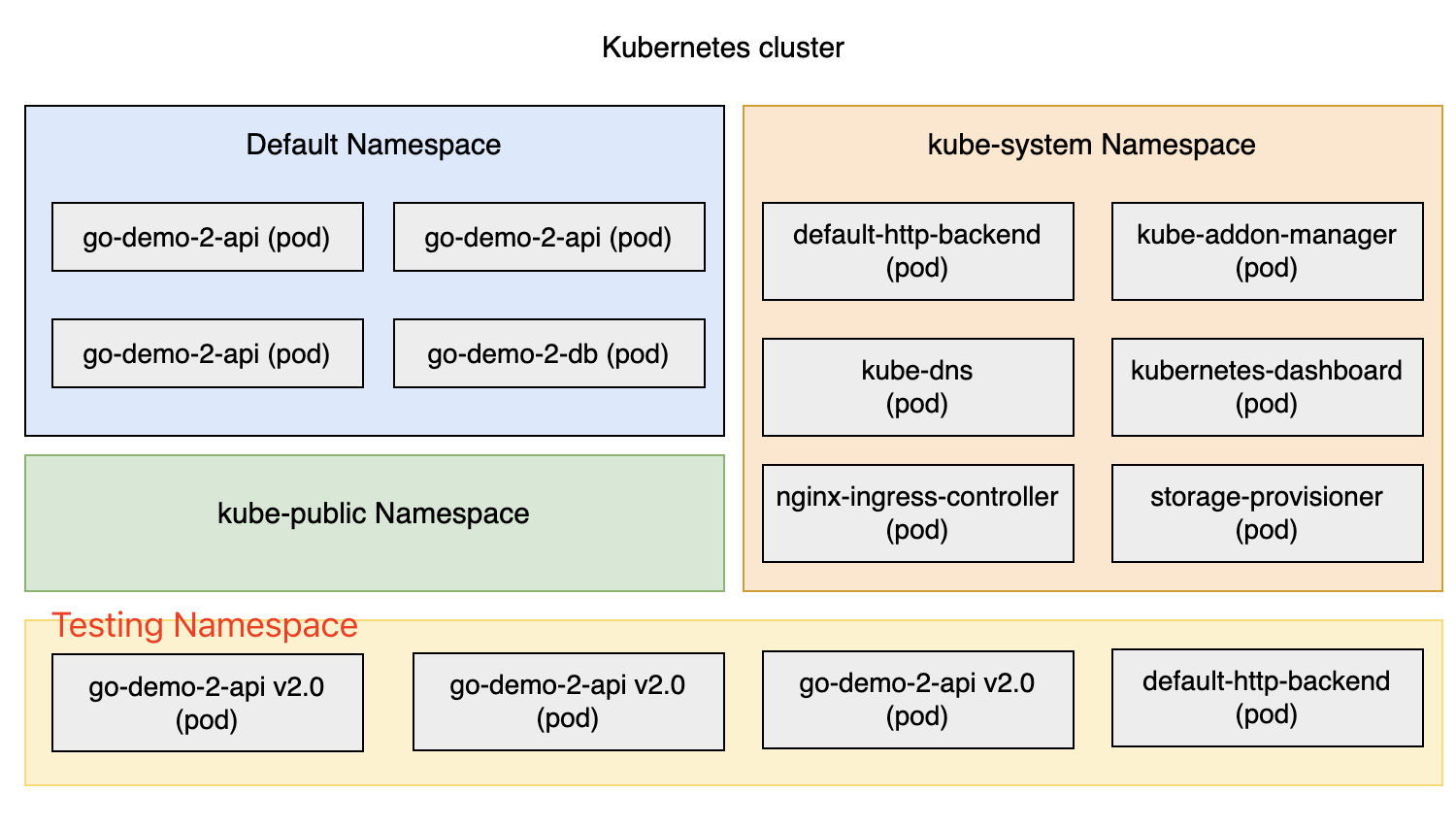
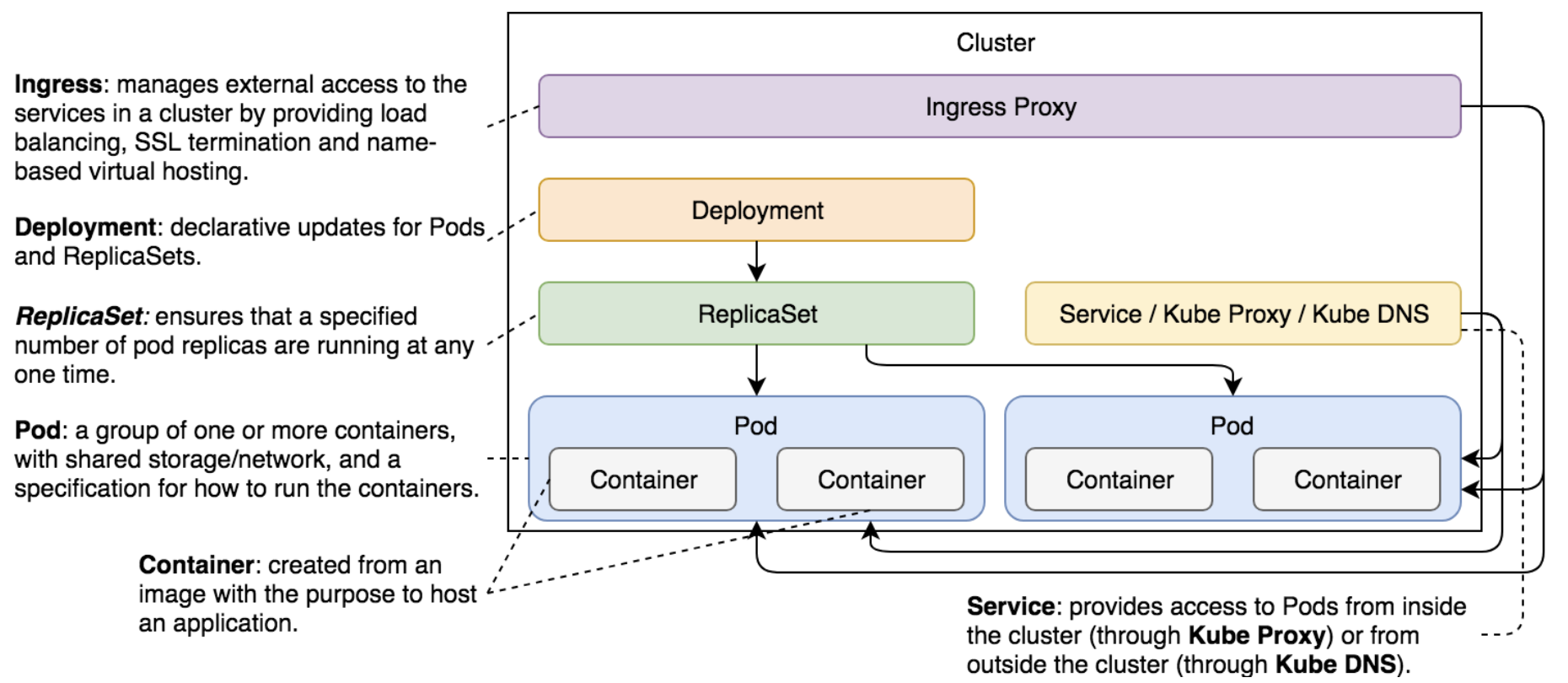
Kubernetes 理论与实践-1-基础-Pods, ReplicaSets, Services, Deployments, IngressJuly 9, 2025 · 19 min read一点历史 在物理服务器时代,基础设施管理和部署是合在一起的,因为所有的设置是不可变的,只要安装后基本不会改变;有了 VM 和 镜像后,基础设置管理和部署可以分开,这就能够让原本在福 wish 昂不可变的应用设置获得一定程度的可变性。 后来,Chef, Puppet, Ansible 陆续发展以支持基础设施管理(基础设施状态管理),但是却没有花更多到部署那块。为了支持可变性,Packer 应运而生;发展至今,现在的答案是 Terraform, Packer, CloudFormation。 部署流程中,在 Docker 和容器没有出现之前,我们有 Linux 和 cGroup,但是它很难用;再之前是一堆专注于基础设置管理的软件(Puppet, CFEngine, SALTSTACK, Chef, Ansible)。 Docker(容器运行时) 和容器的出现,保证了 容器景象是不可变的情况下,给部署流程带来拥抱可变性的可能;容器很好,不过直接运行容器并不会让你获得高容错和自愈功能,因此需要有一个东西充分利用和安排它们配置到合适的地点,从而体现出扩展性、高稳定性和高可用性。 有了容器之后,部署流程可变后,Schdulers 调度器程序 (MESOS, MARATHON, Docker Swarm, Kubernetes) 应运而生;调度器管理一个集群内多个应用之间的部署交互; Kubernetes 特性