微调 Fine-Tuning
Definition
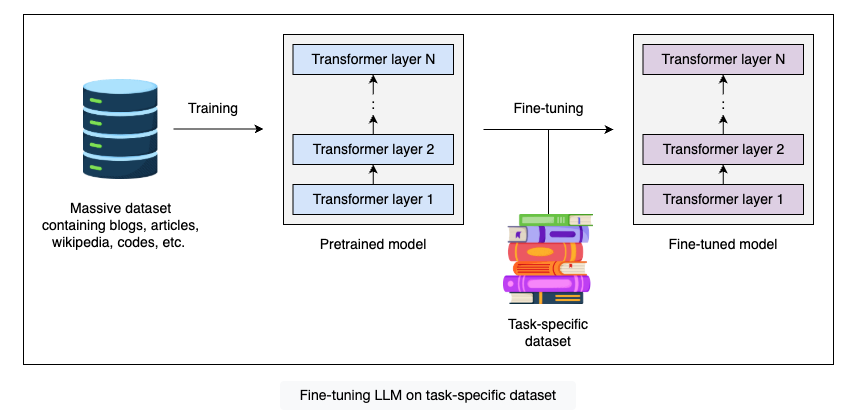
Fine-tuning involves taking a pretrained model that has learned general patterns from large datasets and adjusting its parameters to fit custom, task-specific datasets.
According to our task, we take a dataset smaller than the pretraining data and adjust the model weights to allow it to adapt to the new data. This way, the model refines its existing knowledge and learns the details of the new data. By building on the pretrained model’s knowledge, fine-tuning enables the model to learn more efficiently and accurately.
Training parameters
Configuring the training parameters is important while fine-tuning the model. These parameters play a significant role in controlling how the model learns from our custom dataset and achieves optimal performance while fine-tuning. The following are some parameters that need to be considered for effectively fine-tuning a model:
- Batch size: It is the number of examples processed in one cycle of the training process. The selection of batch size depends on factors such as the size of training data, memory resources, and the complexity of the task. A larger batch size trains more data in one cycle, speeding up the overall training process, but on the other hand, it also requires more memory to process the data.
- Epochs: It is the number of cycles passing through the complete dataset (数据集完整遍历的次数,决定训练时长). Selecting the epoch value also depends on the complexity and size of the training data. Lower value of epochs can result into underfitting while the higher value can result in the overfitting of the model.
- Iteration: It is the number of batches required to complete one epoch. Iterations can be calculated by dividing the total number of examples in training data by the batch size.
- Learning rate: This is used to determine how quickly the model learns from training data. A lower learning rate requires more epochs to reflect the effects, while a higher learning rate will reflect changes faster, even with less epochs.
Steps for fine-tuning
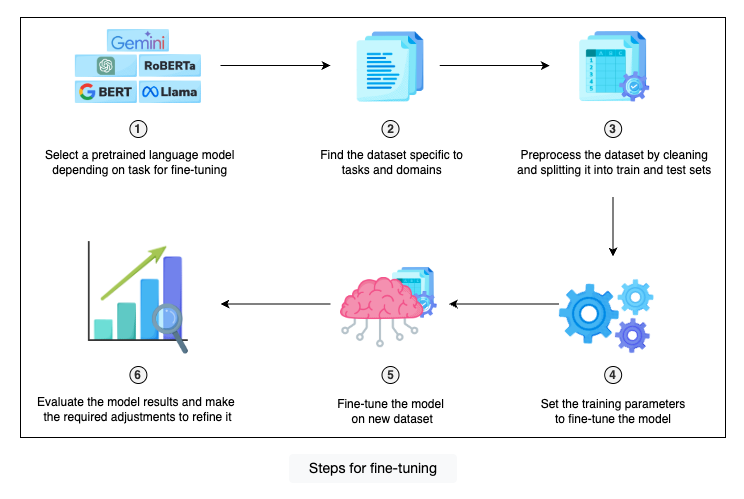
Following are the key steps that we need to perform to fine-tune any LLM:
- Select the model: The first and most important step is to select a pretrained language model depending on our task for fine-tuning. Pretrained models are general-purpose models trained on a large corpus of data. There are a number of open-source (Llama, BERT, and Mistral, etc.) and closed-source (ChatGPT, Gemini, etc.) models available for fine-tuning. We just need to find the model that best fits our resources and requirements.
- Prepare the dataset: Our next step is to find a dataset specific to our tasks and domains. This step is very crucial as the entire fine-tuning depends on the dataset we select. It should be structured and arranged so the model can learn from it.
- Preprocess the dataset: After preparing the dataset, we need to perform preprocessing on it. This step involves cleaning and then splitting the data into train and test sets. Once the preprocessing is done, our dataset is ready for fine-tuning.
- Configure the training parameters: The next important step is to configure the parameters for fine-tuning the model. This involves setting training parameters such as learning rate, batch size, epochs, etc.
- Fine-tune the model: Now we are all set for fine-tuning the model. The fine-tuning step trains the model on a new dataset while retaining the previous knowledge model from pretraining. This makes the model learn knowledge about our task-specific data.
- Evaluate and refine: The last step is to evaluate the model results to assess its performance according to our task and make any necessary adjustments. After evaluation, our model is ready to be used for the required task.
Types of fine-tuning
Fine-tuning is a powerful technique for adapting pretrained language models to specific tasks and datasets, unlocking their full potential for optimal performance. Different fine-tuning techniques have emerged as the field of natural language processing continues to evolve. Each of them has its own strengths, limitations, and use cases.
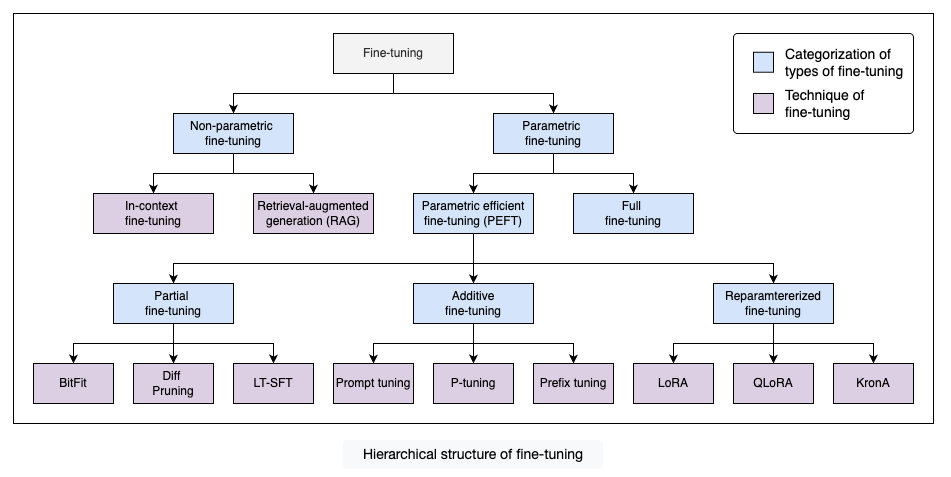
Non-parametric fine-tuning
Non-parametric fine-tuning is the type that works by passing the task-specific data as a context without training any parameters of the model. The model uses the provided contextual information to enhance the model’s accuracy and efficiency on new tasks. This is the cost-effective way of customizing the model with minimal effort and resources.
In-context fine-tuning
在输入中加入例子。
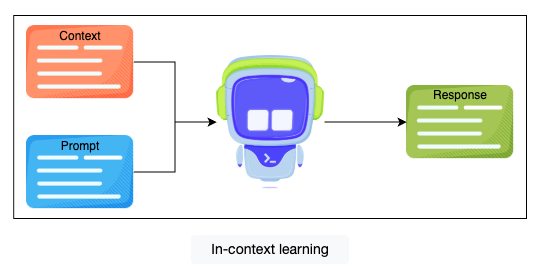
- 好处: 不需要任何微调,只需要额外提供一些数据,节省成本。
- 坏处: 额外提供的信息占用输入窗口(limited context window)的大小,其他输入信息就会少,导致信息丢失。
Retrieval-argmented generation (RAG)
将用户请求拿去外部资料库搜索相关资料,然后一起发给模型。
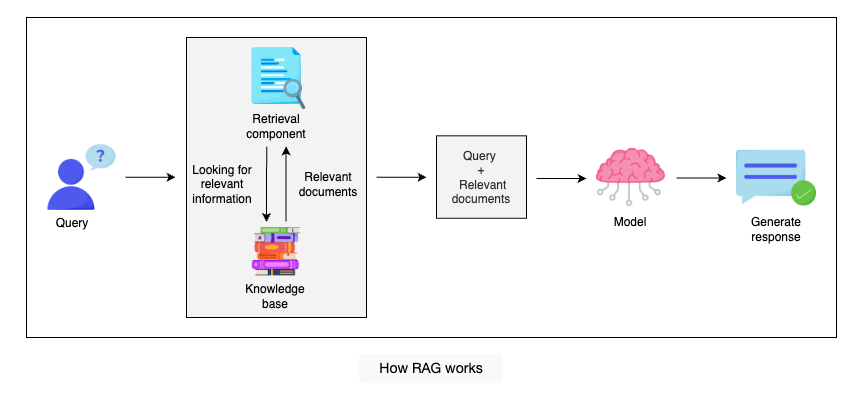
- 好处: 灵活、效率最好的不改变模型参数的方法。
- 坏处: 数据量起来的话,搜索时间会增加。同样存在信息搜索不准确,信息过载的问题,导致大模型整体效率和准确性。
Parametric fine-tuning
Parametric fine-tuning is the type that works by fine-tuning the model’s parameters on task-specific datasets. It can be the training of all the parameters of the model or training only a few parameters by freezing the rest of the parameters of the model.
Full fine-tuning
Full fine-tuning is a technique that involves training all the parameters of all the layers of the model. The model gradually forgets the knowledge from pretraining and learns new knowledge from the task-specific dataset. This is similar to training the model from scratch hence, it requires large computational resources.
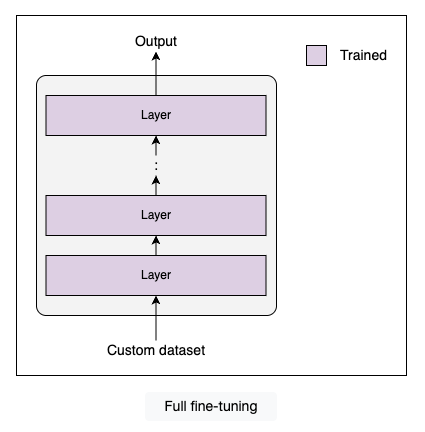
Full fine-tuning has two significant drawbacks: the high computational costs required to train all the parameters and catastrophic forgetting, which causes the model to lose the general knowledge and patterns acquired during pretraining and reduces its overall efficiency.
Full fine-tuning is required when the custom dataset is large and significantly different from the pretraining data, making it necessary to train the model from scratch. For example, fine-tuning a model pretrained on a single language on multilingual data or training a model on a specialized domain like medical or legal texts. Otherwise, there are efficient approaches available to fine-tune the model.
Parametric efficient fine-tuning (PEFT)
Parametric efficient fine-tuning (PEFT) is a technique that involves training the selected or newly added parameters to fine-tune the model. This allows the model to adapt to new tasks with minimal changes in the pretrained model. By training the model on fewer parameters, PEFT actually reduces the computational costs and retains the pretrained knowledge, making it an attractive approach for fine-tuning.
Partial fine-tuning
A pretrained model learns both general and task-specific details in different layers of the model. Partial fine-tuning, also known as selective fine-tuning, works by freezing the important layers, the layers that have learned general details and patterns of the data, and training only the output layers, which have task-specific details to train the model output on specific tasks. This approach helps the model preserve more of the pretraining knowledge and adapt to task-specific data with minimum training of the model.
-Partial fine-tuning-228c1697a0eb91ddf732bb42a84f06d6.png)
There are many methods to implement partial fine-tuning, including BitFit (Bias-terms Fine-tuning), LT-SFT (Lottery Ticket Sparse Fine-Tuning), Diff Pruning, Threshold-Mask, etc.
Let’s look at the details of some of them.
- BitFit: The bias-terms Fine-tuning (BitFit) method works by training only a small set of the model’s parameters, specifically the bias-terms, and freezing the rest of the model parameters. The bias-terms have a significant impact on the model’s performance, and updating only them results in accuracy similar to full fine-tuning for small to medium-sized training data.
- LT-SFT: The Lottery Ticket Sparse Fine-Tuning (LT-SFT) method involves training only the important weights of the model. It works by first identifying the most important weights obtained by comparing the weights of a fully fine-tuned model on task-specific data with the pretrained model. Then, only fine-tuning the selected top-k weights by creating a binary matrix. LT-SFT requires double effort (full fine-tuning and fine-tuning important weights), but it results in increased efficiency as it only updates the important weights.
Partial fine-tuning saves a lot of computational resources because it only needs to train selected parameters, making it both time and resource-efficient. However, it may not always achieve the same level of task-specific performance as full fine-tuning, especially for complex tasks that require significant adaptations to the model. Additionally, it also risks overfitting to the new task, as updating only selected parameters can lead to learning more about specialized instead of generalized features. Though partial fine-tuning overcomes the issue of catastrophic forgetting by updating selected parameters, there is still a loss of some pretrained knowledge.
To address this limitation, a more advanced PEFT technique, additive fine-tuning, is used.
Additive fine-tuning
Additive fine-tuning involves adding new layers or modules, known as adapters, to the model for fine-tuning. It only trains the newly added trainable parameters without changing the parameters of the pretrained model.
-Additive fine-tuning-f99dabb343cd49b4b6e28817e7e5b5b7.png)
Many methods help us implement additive fine-tuning, including prompt tuning, Prefix Tuning, P-tuning, LST (Ladder Side-Tuning), MPT (Multitask prompt tuning), and PASTA (Parameter-efficient tuning with Special Token Adaptation). Let’s explore a few of them in detail.
- Prompt-tuning: It involves adding the trainable tokens (called prompts) to the input text and training these tokens to adapt to new tasks. It works by concatenating the prompts with the input text and training only the prompt parameters while freezing the pretrained model.
- Prefix-tuning: This involves prepending soft prompts to the hidden states of the multi-head attention layer and fine-tuning them to adapt to new tasks. It works by using a Feed-Forward Network (FFN) to parameterize the soft prompts and fine-tune the prefix parameters while keeping the pretrained model parameters frozen.
This approach is much faster and more efficient for fine-tuning because it focuses on training only the new layer and preserves the complete pretraining knowledge of the model. This makes the approach resource-efficient. However, on the downside, introducing new layers or modules to the model increases its size and complexity. Additionally, there is a potential risk of overfitting because the newly added layers may become too specialized for task-specific data, reducing generalization on other tasks. To address these challenges, reparameterized fine-tuning comes into action.
Reparametrized fine-tuning
The reparameterized fine-tuning technique involves adding or modifying layers of the pretrained model to reduce the number of trainable parameters. It works by reparameterizing the model weights to approximate the original weights while preserving important information. Only reparameterized weights are then trained while freezing the pretrained weights to fine-tune the model.
-Reparametrized fine-tuning-b26305261356b04e1df30dff57c7f3fb.png)
Many methods can be used to implement reparameterized fine-tuning, including LoRA (Low-Rank Adaptation), QLoRA (Quantized LoRA), KronA (Kronecker Adapter), DyLoRA (Dynamic LoRA), AdaLoRA (Adaptive LoRA), etc. Let’s look at the details of some of them.
- LoRA: The Low-Rank Adaptation (LoRA) uses a low-rank transformation technique to reduce the trainable parameters of the pretrained model while preserving important information. This method reparameterizes the original weights (parameters) using two low-rank matrices. The low-rank matrices are then trained, freezing the pretrained weights to fine-tune the model on a new task.
- KronA: The Kronecker Adapter (KronA) works similarly to LoRA, but instead of using low-rank transformation, it uses Kronecker product decomposition to reduce the trainable parameters. The decomposed matrices are trained while freezing the pretrained weights to fine-tune the model on new tasks.
This approach allows the model to efficiently adapt to new tasks without compromising its pretrained knowledge. Like all other techniques, reparameterized fine-tuning has some limitations. It can face challenges such as limited adaptation or underfitting, especially when dealing with complex datasets.
Comparing the types of fine-tuning
Fine-Tuning Techniques Comparison
Fine-Tuning Techniques Comparison
| Technique | Definition | Use Cases | Limitations |
|---|---|---|---|
| Full fine-tuning | Involves training all the parameters of the model. | - Required for highly domain-specific tasks where significant adaptations needed. - Used when the new dataset is large and significantly different from the pre-training data. | - High computational cost - Catastrophic forgetting - Risk of overfitting if the dataset is small |
| Partial fine-tuning | Works by training only the selected parameters while freezing rest of the parameters of the model. | - Suitable for tasks that needs fine-tuning while preserving the pretrained knowledge with minimal computational resources. - Used when the new task is similar to the pre-training tasks and training dataset is not large. | - Limited adaptation to new tasks specially if the task is complex - Risk of overfitting and underfitting |
| Additive fine-tuning | Introduces new layers or modules (adapters) that are fine-tuned for specific tasks while keeping the original pre-trained model frozen. | - Required for scenarios where model efficiency is important, specially when working with multiple tasks or domains. - Used when computational resources are limited. - Used when quick adaptation is needed. | - Increased model size and complexity - Risk of overfitting |
| Reparameterized fine-tuning | Reparameterizes the weights of the model to approximate the original weights while preserving important information and trains only the reparameterized weights freezing the pre-trained model. | - Best for scenarios where fine-tuning needs to be efficient while preserving the pretrained knowledge. - Used when computational resources are limited. | - Limited ability to capture complex relationships and patterns - Risk of underfitting |
Choosing the right fine-tuning technique
We have explored multiple fine-tuning techniques, each with its strengths, limitations, and specific use cases. Selecting the appropriate method is crucial while fine-tuning the model to achieve the desired performance.
The following are some key factors to consider when choosing a fine-tuning technique:
- Model size
- Task complexity
- Computational resources
- Deployment needs
- Preservation of pretrained knowledge