Definition
Instagram is a free social networking application that allows users to post photos and short videos.
Requirements
Functional requirements
- Post Photos and videos: The users can post photos and videos on Instagram.
- Follow and unfollow users: The users can follow and unfollow other users on Instagram.
- Search photos and videos: The users can search photos and videos based on captions and location.
- Generate news feed: The users can view the news feed consisting of the photos and videos (in chronological order) from all the users they follow. Users can also view suggested and promoted photos in their news feed.
Non-functional requirements
- Scalability: The system should be scalable to handle millions of users in terms of computational resources and storage.
- Latency: The latency to generate a news feed should be low.
- Availability: The system should be highly available. Durability Any uploaded content (photos and videos) should never get lost.
- Consistency: We can compromise a little on consistency. It is acceptable if the content (photos or videos) takes time to show in followers’ feeds located in a distant region.
- Reliability: The system must be able to tolerate hardware and software failures.
Resource estimation
- Read-heavy, read posts more than create posts -> a system can fetch the photos and videos on time
Calculation prerequisites
- Storage and bandwidth
- Assume 60 million photos and 35 million videos are shared on Instagram per day.
- We can consider 3 MB as the maximum size of each photo and 150 MB as the maximum size of each video uploaded on Instagram.
- Server count
- We have 1 billion users, with 500 million as daily active users.
- On average, each user sends 20 requests (of any type) per day to our service.
Storage estimation
- 每天有 60 million 的照片和 35 million 的视频被分享,照片最大为 3MB, 视频最大为 150MB: 60 million * 3MB + 35 million * 150MB = 5430TB
- 存储一年需要的空间是: 5430TB * 365 天 = 1981.85PB

Bandwidth estimation
- (对于服务器来说)一天我们需要下载 5430TB 的数据,因为用户需要上传到我们的服务器中: 5430TB/(24*60*60)s ~= 62.84GB/s ~= 502.8 Gbps
- 如果我们假设读帖子和上传帖子的比例是 100 : 1 的话,我们会有 502.8 Gbps * 100 ~= 50.28 Tbps 的上传速度,从服务器传到用户的手机上
- 总带宽需求: 502.8 Gbps + 50.28 Tbps ~= 50.78 Tbps

GB: Gigabyte
Gb: Gigabit
Server count
- A uniform request distrubution: all the requests are distributed uniformly over a day (lower bound)
- A peak load: all the requests of a day show up simultaneously (upper bound)
Condition
- 500 million user
- 8000 requests/s for one server
Server count assuming uniform request distribution
- 20 requests per user: 500 million * 20 = 10 billion
- 8000 requests/s * (24 * 60 * 60)s = 691.2 million
- 10 billion / 691.2 million ~= 14.47 servers -> 15 servers
Server count assuming peak load
- 1 request per user: 500 million * 1 = 500 million requests
- 500 million per second / 8000 requests per second = 62500 servers
请求有 cpu-bound 与 IO-bound 类型之分,如果用户的请求里面不同的比例会导致最终的计算结果也不同,instagram 的例子中 I/O 类型的请求会多一些,不过为了计算简单,我们假设所有的请求类型是一样的,50 对 50 比例:
- CPU-bound 任务的例子
- 科学计算:使用复杂的数学模型进行模拟和分析,如天体物理学的模拟或蛋白质结构的计算。
- 数据加密与解密:对数据执行加密算法,如 AES 或 RSA。
- 图像或视频渲染:图形处理,如 3D 图像渲染或视频编码转换。
- 机器学习训练:训练大型机器学习模型涉及到大量矩阵运算和数值优化。
- IO-bound 任务的例子
- Web 服务器响应请求:处理用户请求时,主要等待的是网络 I/O 的完成。
- 数据库操作:读取或写入大量数据到磁盘上的数据库。
- 文件处理:从硬盘读取或向硬盘写入大型文件,如日志处理或数据备份。
- 网络数据传输:下载或上传大文件,如 FTP 文件传输。
Design
High-level design
Our system should allow us to upload, view, and search images and videos at a high level. To upload images and videos, we need to store them, and upon fetching, we need to retrieve the data from the storage. Moreover, the users should also be allowed to follow each other.
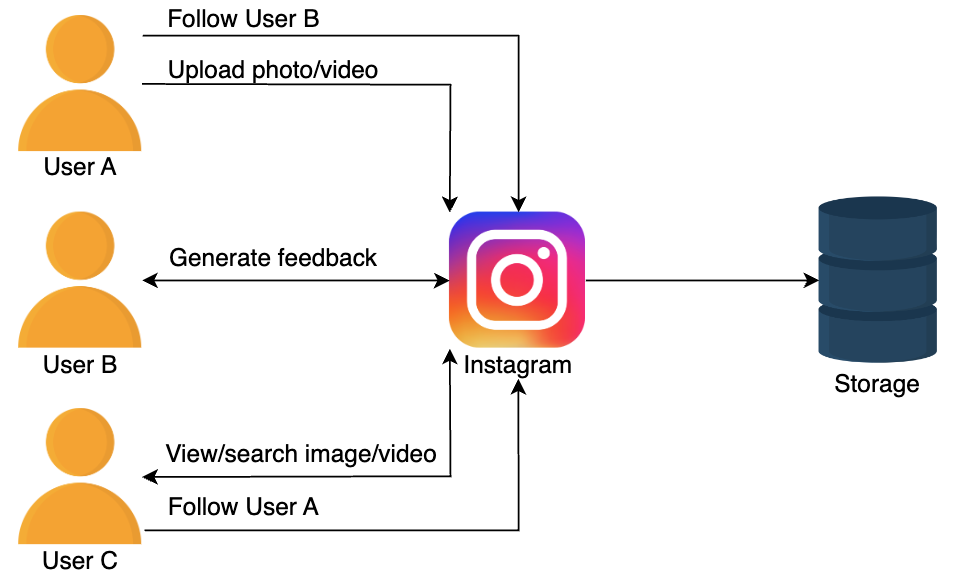
API design
- Post photos and videos
- Follow and unfollow users
- Like or dislike posts
- Search photos and videos
- Generate a news feed
All of the following calls will have a userID, that uniquely specifies the user performing the action.
Post photos and videos
/postMedia API:
postMedia(userID, media_type, list_of_hashtags, caption);
media_type: It indicates the type of media (photo or video) in a post.list_of_hashtags: It represents all hashtags (maximum limit 30 hashtags) in a post.caption: It is a text (maximum limit is 2,200 characters) in a user's post.
Follow and unfollow users
/followUser and /unfollowUser API:
followUser(userID, target_userID);
unfollowUser(userID, target_userID);
target_userID: It indicates the user to be followed.
Like or dislike posts
/likePost and /dislikePost API:
likePost(userID, post_id);
dislikePost(userID, post_id);
post_id: It specifies the post's unique ID.
Search photos and videos
/searchPhotos API:
searchPhotos(userID, keyword);
keyword: It indicates the string (username, hashtag, and places) typed by the user in the search bar.
Generate a news feed
/viewNewsfeed API:
viewNewsfeed(userID, generate_timeline);
generate_timeline: It indicates the time when a user requests news feed generation. Instagram shows the posts that are not seen by the user between the last news feed request and current new feed requests.
Storage schema
Our data is inherently relational, and we need an order for the data (posts should appear in chronological order) and no data loss even in case of failures (data durability). Moreover, in our case, we would benefit from relational queries like fetching the followers or images based on a user ID. Hence, SQL-based databases fulfill these requirements.
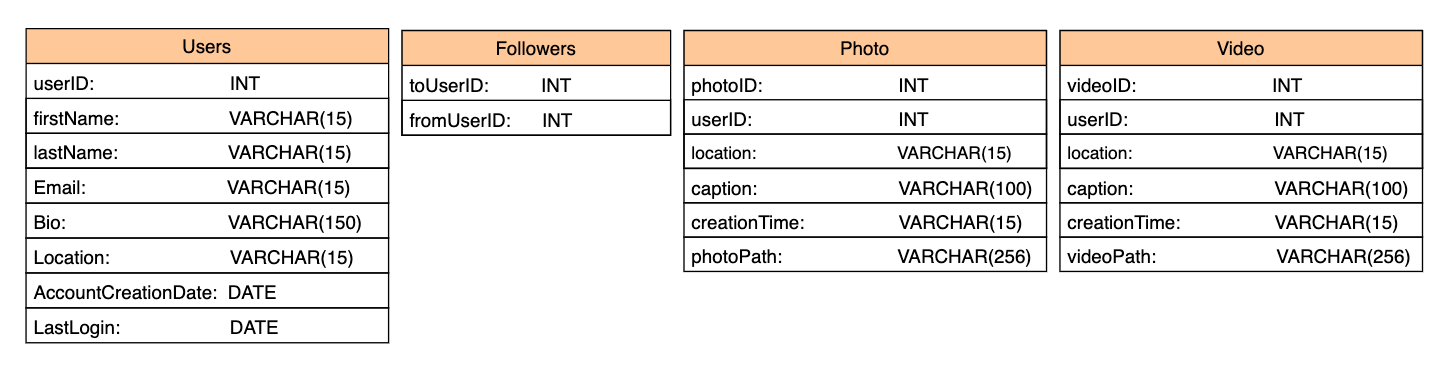
Define tables
- Users: This stores all user-related data such as
ID,name,email,bio,location,date of account creation,time of the last login, and so on. - Followers: This stores the relations of users. In Instagram, we have a unidirectional relationship, for example, if user A accepts a follow request from user B, user B can view user A’s post, but vice versa is not valid.
- Photos: This stores all photo-related information such as
ID,location,caption,time of creation, and so on. We also need to keep the user ID to determine which photo belongs to which user. Theuser IDis a foreign key from the users table. - Videos: This stores all video-related information such as
ID,location,caption,time of creation, and so on. We also need to keep the user ID to determine which video belongs to which user. Theuser IDis a foreign key from the users table.
Data estimation
Let’s figure out how much data each table will store. The column per row size (in bytes) in the following calculator shows the data per row of each table. It also calculates the storage needed for the specified counts.
For example, the storage required for 500 million users is 111000 MB, 2000 MB for 250 followers of a single user, 23640 MB for 60 million photos, and 13790 MB for 35 million videos.

INT 是 4 个字节(bytes)
DATE 是 4 个字节
VARCHAR(15) 是 15 个字节
Detailed Design of Instagram
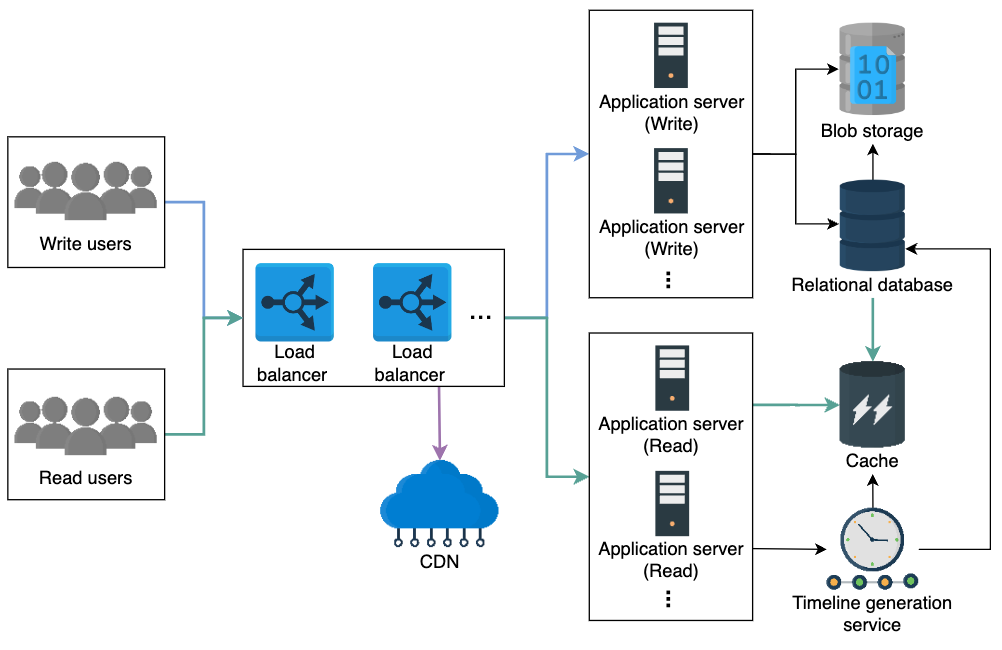
Add more components
- Load balancer: To balance the load of the requests from the end users.
- Application servers: To host our service to the end users.
- Relational database: To store our data.
- Blob storage: To store the photos and videos uploaded by the users.
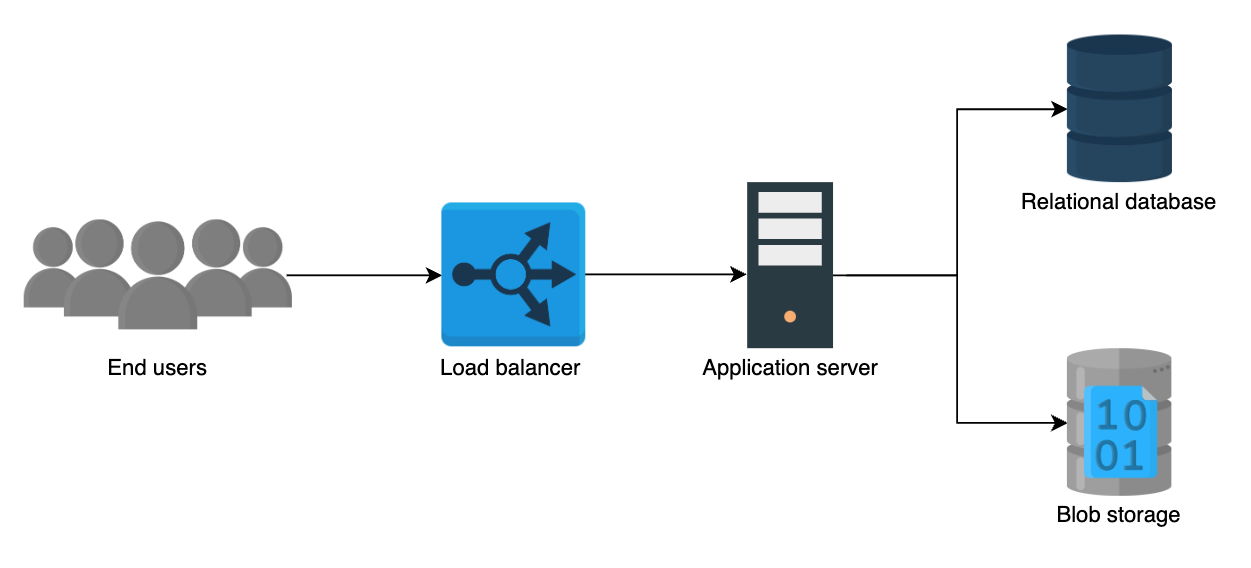
Upload, view, and search a photo
- 上传内容会通过后端服务器向 SQL 关系型数据库插入数据,并上传图片或视频,上传成功后,图片会发送给用户。上传失败,用户会被告知上传失败。
- 读取内容的过程与上面相同,用户能够提供
keyword搜索特定内容。 - 由于系统中有大量的读取需求和少量上传需求,所以我们可以将两个操作分开。
- 我们可以在读取操作的过程中添加缓存,加快读取的延迟。并在前端适用 lazy loading 懒加载的方式,这样不会影响用户体验,在用户浏览的过程中加载图片和视频资源。

Generate a timeline
Now our task is to generate a user-specific timeline.
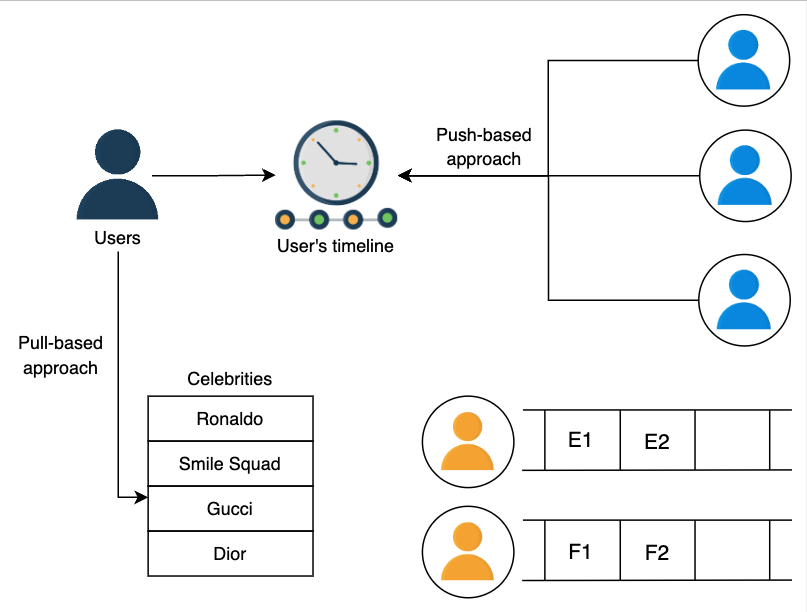
The pull approach
When a user opens their Instagram, we send a request for timeline generation. First, we fetch the list of people the user follows, get the photos they recently posted, store them in queues, and display them to the user. But this approach is slow to respond as we generate a timeline every time the user opens Instagram.
We can substantially reduce user-perceived latency by generating the timeline offline. For example, we define a service that fetches the relevant data for the user before, and as the person opens Instagram, it displays the timeline. This decreases the latency rate to show the timeline. Let’s take a look at the slides below to understand the problem and its solution.

大多数人是不发帖子的,所以会有很多人的 pull 请求是空。
The push approach
In a push approach, every user is responsible for pushing the content they posted to the people’s timelines who are following them. In the previous approach, we pulled the post from each follower, but in the current approach, we push the post to each follower.
Now we only need to fetch the data that is pushed towards that particular user to generate the timeline. The push approach has stopped a lot of requests that return empty results when followed users have no post in a specified time.
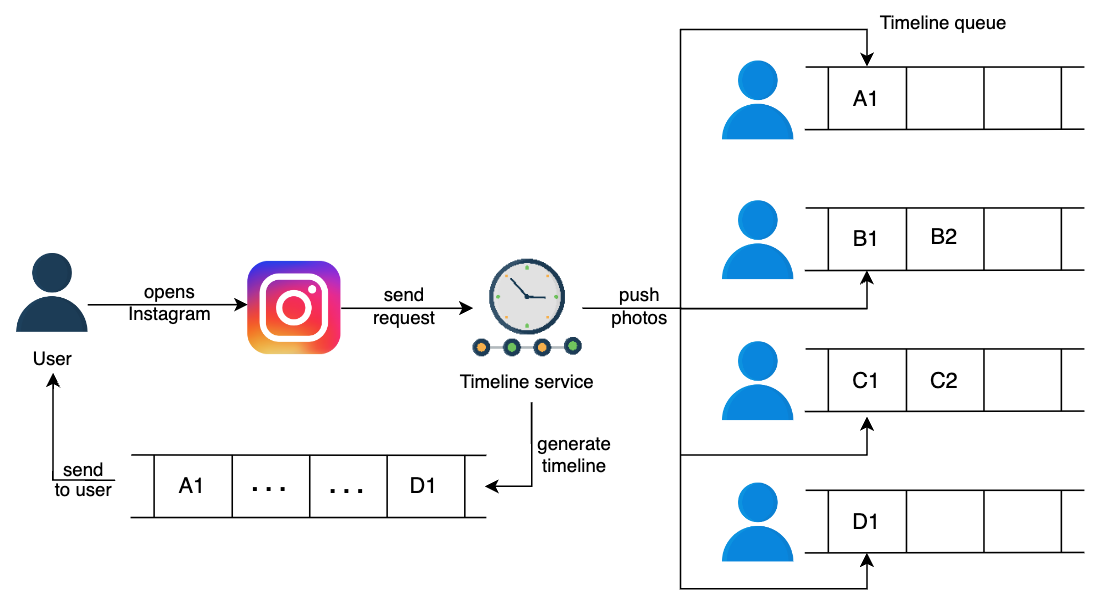
对于拥有 10 亿粉丝特别多的人,每次发帖子都需要为 10 亿个粉丝推送帖子,效率太低。
Hybrid approach
- Push-based users: The users who have a followers count of hundreds or thousands.
- Pull-based users: The users who are celebrities and have followers count of a hundred thousand or millions.
The timeline service pulls the data from pull-based followers and adds it to the user’s timeline. The push-based users push their posts to the timeline service of their followers so the timeline service can add to the user’s timeline.
We have used the method which generates the timeline, but where do we store the timeline? We store a user’s timeline against a userID in a key-value store. Upon request, we fetch the data from the key-value store and show it to the user. The key is userID, while the value is timeline content (links to photos and videos). Because the storage size of the value is often limited to a few MegaBytes, we can store the timeline data in a blob and put the link to the blob in the value of the key as we approach the size limit.
We can add a new feature called story to our Instagram. In the story feature, the users can add a photo that stays available for others to view for 24 hours only. We can do this by maintaining an option in the table where we can store a story’s duration. We can set it to 24 hours, and the task scheduler deletes the entries whose time exceeds the 24 hours limit.
Finalized design
We’ll also use CDN (content delivery network) in our design. We can keep images and videos of celebrities in CDN which make it easier for the followers to fetch them. The load balancer first routes the read request to the nearest CDN, if the requested content is not available there, then it forwards the request to the particular read application server (see the “load balancing chapter” for the details). The CDN helps our system to be available to millions of concurrent users and minimizes latency.
Ensure non-functional requirements#
We evaluate the Instagram design with respect to its non-functional requirements:
- Scalability: We can add more servers to application service layers to make the scalability better and handle numerous requests from the clients. We can also increase the number of databases to store the growing users’ data.
- Latency: The use of cache and CDNs have reduced the content fetching time.
- Availability: We have made the system available to the users by using the storage and databases that are replicated across the globe.
- Durability: We have persistent storage that maintains the backup of the data so any uploaded content (photos and videos) never gets lost.
- Consistency: We have used storage like blob stores and databases to keep our data consistent globally.
- Reliability: Our databases handle replication and redundancy, so our system stays reliable and data is not lost. The load balancing layer routes requests around failed servers.